Спарк характеристика: Технические характеристики Шевроле Спарк: габариты, клиренс (дорожный просвет) и другие параметры Chevrolet Spark — размер шин и другие ттх и параметры | Автоцентр Сити
| Двигатель, л |
1,0 МТ(АТ) |
1,2 МТ |
| Макс. мощность кВт (или л.с.) при … оборотах/мин |
68/6400 |
81/6400 |
| Макс. крутящий момент Нм при … оборотах/мин |
93/4800 |
111/4800 |
| Масса | ||
| Снаряженная масса, кг |
857 |
857 |
| Полезная нагрузка, кг |
510 |
510 |
| Динамика | ||
| Макс. скорость, км/ч |
151(143) |
162 |
| Разгон 0-100км/ч , с |
15,3(17,5) |
12,9 |
| Расход топлива | ||
| В городе, л/100км |
7,1(8,2) |
7. |
| На трассе, л/100км |
4,6(5,1) |
4,6 |
| В среднем, л/100км |
5,5(6,3) |
5,4 |
| Наружные размеры | ||
| Длина, мм |
3640 |
3640 |
| Ширина, мм |
1597 |
1597 |
| Высота, мм |
1522 |
1522 |
| Клиренс, мм |
135 |
135 |
| Диаметр разворота, м |
9,8 |
9,8 |
| Багажник, топливный бак | ||
| Объём багажника, л |
170 |
170 |
| Объём багажника со сложенным задним сиденьем, л |
н/д |
н/д |
| Объём топливного бака, л |
35 |
35 |
 0
0Обзор Chevrolet Spark 2019-2020 — технические характеристики и фото
Обзор нового Chevrolet Spark 2019-2020: внешний вид, интерьер, технические характеристики, комплектации, параметры, системы безопасности и цена. В конце статьи фото и видео-обзор Chevrolet Spark.Обзор нового Chevrolet Spark 2019-2020: внешний вид, интерьер, технические характеристики, комплектации, параметры, системы безопасности и цена. В конце статьи фото и видео-обзор Chevrolet Spark.
В конце статьи фото и видео-обзор Chevrolet Spark.Обзор нового Chevrolet Spark 2019-2020: внешний вид, интерьер, технические характеристики, комплектации, параметры, системы безопасности и цена. В конце статьи фото и видео-обзор Chevrolet Spark.
Содержание обзора:
Компактные автомобили в наши дни не менее популярны, чем большие и громоздкие внедорожники. В большинстве случаев такие автомобили идеально подходят для езды по городу и поездок загород. Пример тому компактный хэтчбек Chevrolet Spark, на первый взгляд кажется, что автомобиль 3-ох дверный, на самом же деле 5-ти дверный.
Последняя, четвертая генерация Chevrolet Spark была представлена еще в 2015-ом году, на автомобильной выставке в Нью-Йорке, но по разным причинам в продажу поступило только в середине 2017-го. По маркировке производителя, хэтчбек Chevrolet Spark числится под индексом M400, в сравнении с третей генерацией это полностью новый автомобиль, с более строгим взглядом и стилем. Изменения новой четвертой генерации видны даже неопытному автолюбителю.
Все же новый Chevrolet Spark по-прежнему миниатюрный автомобиль, поэтому не стоит ожидать просторного багажного отделения и мощного двигателя под капотом. По пространству интерьер Chevrolet Spark остался таким же, но более просторным для второго ряда сидений. Середина 2018 года стала для автомобиля перевалочной, так как производитель представил обновленный вариант Chevrolet Spark 2019, изменились отдельные детали спереди и позади, остальное же прежнее, как и до обновления.
Конкуренты:
Экстерьер хэтчбека Chevrolet Spark 2019-2020
Внешний вид Chevrolet Spark 2019-2020 каждой деталью кузова говорит о компактном и экономном стиле автомобиля. Если сравнивать третью и четвертую генерацию хэтчбека, то в большей части изменения пришлись на переднюю и заднюю часть, боковая сторона автомобиля получила минимум нового. Спереди новый Chevrolet Spark получил более строгие черты, передняя оптика получила раздельные детали с линзами по центру. Для придания большей злости и выразительности, фон передней оптики сделали только черным, хромированные варианты исключены, к тому же если сравнивать Chevrolet Spark до рестайлинга и после, то изменения так же заметны.
После обновления оптика получила хромированные ресницы, они же служат окантовкой для верхней решетки радиатора. Основой для оптики послужили ксеноны, в более дорогих комплектациях Chevrolet Spark 2019-2020 производитель установил полностью светодиодную оптику. Решетка радиатора, как и ранее, разделена на две части, верхняя поменьше, нижняя же основная и занимает почти всю переднюю часть хэтчбека. Изменения пришлись и на передний бампер Chevrolet Spark 2019, по сторонам дизайнеры добавили LED ходовые огни, на пару с небольшими противотуманками и пластиковыми вставками. В зависимости от комплектации Chevrolet Spark, данная часть бампера может меняться, к примеру противотуманки могут быть круглой формы на пару с LED ходовыми огнями.
Капот новой генерации Chevrolet Spark 2019, как основная передняя часть получил строгие черты, в частности в районе передней оптики. Дополнительно дизайнеры приподняли центральную часть капота, придав еще больше «злости» компактному Chevrolet Spark 2019.
Боковая часть нового Chevrolet Spark 2019 получила минимум изменений. Как и в предыдущей модели, задняя дверь практически незаметна и на первый взгляд кажется, что автомобиль трехдверный. Такой эффект получился за счет скрытой дверной ручки для задней двери, её расположили возле заднего стекла. От передней арки колеса и до середины задних дверей тянется линия, еще одна L-образная линия тянется вдоль задней арки колес. Вместо молдингов, на нижней части дверей дизайнеры добавили небольшую выемку. Все же, доплатив $230 производитель может установить молдинги на Chevrolet Spark 2019-2020, черные или хромированные.
С декоративных элементов Chevrolet Spark 2019-2020 можно отметить хромированную окантовку вокруг боковых стекол, дверные ручки по стандарту окрашены под цвет кузова, за отдельную доплату, ручка передних дверей может быть хромированной. Больше всего изменений пришлось на боковые зеркала заднего вида, корпус стал вытянутым, к тому же улучшили функционал. В стандартный набор входит электропривод регулировки и автоматическое складывание. Опционально или топ комплектации получат подогрев, LED повторители поворотов и память на несколько режимов. Окрас корпуса зеркал одинаковых для всех вариантов Chevrolet Spark 2019-2020, верхняя часть в цвет кузова, нижняя в черный цвет.
Больше всего изменений пришлось на боковые зеркала заднего вида, корпус стал вытянутым, к тому же улучшили функционал. В стандартный набор входит электропривод регулировки и автоматическое складывание. Опционально или топ комплектации получат подогрев, LED повторители поворотов и память на несколько режимов. Окрас корпуса зеркал одинаковых для всех вариантов Chevrolet Spark 2019-2020, верхняя часть в цвет кузова, нижняя в черный цвет.
Расцветка кузова Chevrolet Spark 2019-2020 особо не отличается от предыдущей модели:
- синий металлик;
- серебристый;
- белый;
- черный;
- фиолетовый;
- красный;
- темно-серый;
- оранжевый;
- малиновый;
- бежевый.
Несмотря на обновленный кузов, сочетание размера колес и кузова соблюдено в полной мере. Основой для нового хэтчбека Chevrolet Spark послужили 15″ стальные диски с декоративными колпаками, более дорогие варианты обзавелись 15″ легкосплавными дисками с шинами 185/55. По желанию покупатель Chevrolet Spark 2019-2020 опционально может установить диски на 16″, но еще большего диаметра производитель не рекомендует, так как могут быть проблемы с управлением.
По желанию покупатель Chevrolet Spark 2019-2020 опционально может установить диски на 16″, но еще большего диаметра производитель не рекомендует, так как могут быть проблемы с управлением.
Задняя часть нового хэтчбека Chevrolet Spark 2019-2020 осталась такой же, как и до изменений. Основную часть отвели крышки багажника, верхнюю часть украшает небольшой спортивный спойлер с LED повторителем стопов и стеклоочиститель. Само ж стекло небольшое и выполнено в спортивной форме. Больше всего на задней части Chevrolet Spark 2019-2020 выделили стопы, в зависимости от комплектации они могут быть галогенными или светодиодными, с хорошо выраженными элементами.
Последняя деталь задней части – бампер, чтоб оригинально подчеркнуть дизайн, на всю ширину бампера добавили С-образную выемку, в нее ж поместили две небольшие противотуманки. Выхлопная система Chevrolet Spark 2019 спрятана за задним бампером, хотя, по отзывам владельцев, требует доработки, так как на фоне белого кузова со временем видна сажа.
Крыша нового хэтчбека Chevrolet Spark 2019-2020 достаточно простая. По стандарту максимум, что украшает крышу – это небольшая штыревая антенна. В топ комплектациях антенна будет в виде акульего плавника, а так же появятся рейлинги для крепежа дополнительного багажника. В зависимости от выбранной комплектации, крыша компактного хэтчбека Chevrolet Spark 2019-2020 может быть сплошной, с люком на электроприводе или же панорамной (за последнюю необходимо доплатить $1000).
Обновленный хэтчбек Chevrolet Spark 2019-2020 получил небольшое, но значительное количество изменений. Строгий вид, современный функционал и особый новый характер сыграли только позитивную роль для новинки. Все же автомобиль по-прежнему идеален для городского движения и экономный по затратам на топливо.
Интерьер нового Chevrolet Spark 2019-2020
Салон нового хэтчбека Chevrolet Spark 2019-2020 получил меньше изменений. Несмотря на компактные габариты и относительно небольшую цену, внутри автомобиля можно найти современные технологии. Дизайнеры максимально подогнали качество хэчтбека, при этом не выходя за рамки установленного бюджета автомобиля.
Дизайнеры максимально подогнали качество хэчтбека, при этом не выходя за рамки установленного бюджета автомобиля.
Центральная панель
Сразу под дисплеем расположилась небольшая панель управления аудиосистемой и мобильной связью. Немного ниже два воздуховода и панель климат-контроля, на первый взгляд все выглядит скудно, но большую часть управления перенесли на основной дисплей. Заканчивается центральная часть панели небольшим углублением, предназначенным для подзарядок от USB порта и розетки на 12V.
Весьма простым получился центральный тоннель Chevrolet Spark между передними сиденьями. Дизайнеры установили только основные и самые необходимые детали: механический ручник, два подстаканника, рычаг коробки передач и подлокотник (опционально для топ комплектаций). Чтоб приукрасить переднюю панель, дизайнеры предлагают на выбор основную вставку по периметру центральной консоли, а так же пару вставок по сторонам панели.
Интерьер хэтчбека Chevrolet Spark 2019-2020 в зависимости от комплектации рассчитан на посадку 4-ох или 5-ти пассажиров. Передние сиденья новинки получили более спортивную форму, нежели до рестайлинга, неплохая боковая поддержка, высокие подголовники и удобная посадка. Регулировка передних сидений может быть механической или электронной, с помощью механики отрегулировать можно в 6-ти направлениях водительское и в 4-ох направлениях пассажирское сиденье. С помощью электропривода регулировка водительского сиденья доступна в 8-ми направлениях (в том числе и поперек в районе поясницы). Среди функционала сидений Chevrolet Spark 2019-2020 можно отметить подогрев и память водительского сиденья на три режима.Второй ряд сидений Chevrolet Spark 2019-2020 по стандарту рассчитан на посадку трех пассажиров, топ комплектации ж рассчитаны на двух пассажиров. Причина тому появление подстаканника и небольшой выемки для мелочей и подзарядка от USB порта. Чтоб не заморачиватся с расположением деталей, дизайнеры вмонтировали этот набор в центральную часть сиденья, тем самим, исключив возможность посадки пассажира. Пропорция складывания сидений стандартная 60/40, в том числе и для топ комплектации. Несмотря на компактные габариты Chevrolet Spark 2019-2020, места для пассажиров второго ряда предостаточно.
Среди функционала сидений Chevrolet Spark 2019-2020 можно отметить подогрев и память водительского сиденья на три режима.Второй ряд сидений Chevrolet Spark 2019-2020 по стандарту рассчитан на посадку трех пассажиров, топ комплектации ж рассчитаны на двух пассажиров. Причина тому появление подстаканника и небольшой выемки для мелочей и подзарядка от USB порта. Чтоб не заморачиватся с расположением деталей, дизайнеры вмонтировали этот набор в центральную часть сиденья, тем самим, исключив возможность посадки пассажира. Пропорция складывания сидений стандартная 60/40, в том числе и для топ комплектации. Несмотря на компактные габариты Chevrolet Spark 2019-2020, места для пассажиров второго ряда предостаточно.
Материал для обшивки интерьера нового Chevrolet Spark самый разнообразный. В зависимости от выбранной комплектации производитель предлагает тканевую или кожаную обшивку. В отличии от хэтчбека до рестайлинга, обшивка новинки не столь яркая и исключает большое число комбинаций ткани и кожи. Тканевая обшивка интерьера доступна в оттенках:
Тканевая обшивка интерьера доступна в оттенках:
- черный;
- бежевый;
- серый.
Помимо самой расцветки, дизайнеры могут добавить определенный рисунок или стиль. Что касается кожаной обшивки, то перечень пока минимальный – черный, коричневый или бежевый. Прострочка сидений Chevrolet Spark 2019-2020, как правило, пропорционально наоборот от расцветки самых сидений. Зачастую прострочка красная, белая или черная. По словам производителя, расширять перечень оттенков интерьера и варианты материалов обшивки в планы не входит. Хотя доплатив $1200, опционально все же можно заказать другой вариант отделки интерьера или же нестандартный вариант. В дополнение к общему дизайну производитель предлагает на выбор разные вставки под дерево, карбон или полированный алюминий по периметру хэтчбека.
Водительское место Chevrolet Spark 2019-2020, по сути, осталось прежним и выполнено по всем канонам бренда. Панель приборов компактного хэтчбека выделяется большим стрелочным спидометров по центру, немного меньшим по размеру тахометром и небольшим монохромным дисплеем бортового компьютера. Панель по-прежнему хорошо просматривается любое время суток и погоду.
Панель по-прежнему хорошо просматривается любое время суток и погоду.
Рулевое колесо хэчтбека Chevrolet Spark 2019-2020 нечем не отличается от других автомобилей бренда, разве что немного меньше в диаметре. В основе руля лежит три спицы, две боковые отведены под функциональные кнопки и управление мобильной связью. Отрегулировать руль можно по высоте и по глубине, в базе с помощью механического привода, в топ версиях с помощью электропривода. Для более удобного управления система Chevrolet Spark 2019-2020 слева от руля расположили небольшую панель световых приборов и систем безопасности.
Салон обновленного Chevrolet Spark 2019-2020 порадует любителей небольших автомобилей с минимальным числом кнопок. Дизайнеры не стали кардинально менять интерьер хэчтбека, так от предыдущей генерации он получил положительные отзывы, а так же неплохо зарекомендовал себя среди конкурентов.
Технические характеристики Chevrolet Spark 2019-2020
Так как Chevrolet Spark 2019-2020 компактный и в большей части городской автомобиль, то соответственно ожидать мощных двигателей не стоит. На выбор покупателю предоставили два бензиновых агрегата (объемом 1,0 и 1,4 л.), а так же механическую и автоматическую коробку передач. Привод обновленного хэтчбека Chevrolet Spark 2019-2020 только передний.
На выбор покупателю предоставили два бензиновых агрегата (объемом 1,0 и 1,4 л.), а так же механическую и автоматическую коробку передач. Привод обновленного хэтчбека Chevrolet Spark 2019-2020 только передний.
| Технические характеристики Chevrolet Spark 2019-2020 | ||
| Двигатель | DVS | LV7 |
| Топливо | бензин | бензин |
| Объем, л | 1,0 | 1,4 |
| Мощность, л.с. | 75 | 98 |
| Крутящий момент, Нм | 93 | 128 |
| Трансмиссия | 5 ст. МКПП или CVT | 5 ст. МКПП или CVT |
| Привод | передний | передний |
| Расход топлива Chevrolet Spark 2019-2020 | ||
| По городу, л. | 6,9 — 7,0 | 7,5 |
| По трассе, л. | 6,2 | 6,7 |
| Смешанный цикл, л. | 6,7 | 7,0 |
| Габариты хэтчбека Chevrolet Spark 2019-2020 | ||
| Длина, мм | 3595 | |
| Ширина, мм | 1595 (без учета зеркал) | |
| Высота, мм | 1485 | |
| Колесная база, мм | 2385 | |
| Колея передних колес, мм | 1410 | |
| Колея задних колес, мм | 1418 | |
| Объем бака, л | 32 | |
| Объем багажника, л | 314 | |
| Снаряженный вес, кг | 900 | |
Как и гамма двигателей, подвеска Chevrolet Spark 2019-2020 не получила изменения. Спереди установлена независимая подвеска типа McPherson, позади многорычажная подвеска, аналогичная структура установлена в новом Chevrolet Cruze Hatchback 2019. Относительно тормозной системы, то тут зависит все от дисков. Для стальных дисков спереди дисковые тормоза, позади барабанные тормоза, комплектации с легкосплавными дисками получили дисковые вентилируемые тормоза на все 4 колеса.
Спереди установлена независимая подвеска типа McPherson, позади многорычажная подвеска, аналогичная структура установлена в новом Chevrolet Cruze Hatchback 2019. Относительно тормозной системы, то тут зависит все от дисков. Для стальных дисков спереди дисковые тормоза, позади барабанные тормоза, комплектации с легкосплавными дисками получили дисковые вентилируемые тормоза на все 4 колеса.
Опционально, за отдельную плату производитель предлагает добавить множество аксессуаров на новый Chevrolet Spark 2019-2020. Доплатив $129, салон хэтчбека укомплектуют беспроводной Bluetooth гарнитурой, за $30 производитель укомплектует полным набором шнуров для подзарядки самых разнообразных гаджетов. Изначально салон Chevrolet Spark 2019-2020 не рассчитан для курящих пассажиров, поэтому за доплату в $60 будет установлена пепельница в виде стакана и прикуриватель от розетки 12V.
Безопасность и комфорт Chevrolet Spark 2019-2020
Небольшое обновление пришлось на системы безопасности и комфорта хэтчбека Chevrolet Spark 2019-2020, помимо перечня систем предыдущей модели, производитель добавил новые системы, часть из которых теперь входят в стандартный набор автомобиля. Среди систем безопасности и комфорта максимальной комплектации числятся:
Среди систем безопасности и комфорта максимальной комплектации числятся:
- передние и боковые подушки безопасности;
- шторки безопасности;
- подушка безопасности в районе коленей водителя;
- система автоматического торможения в случае ДТП;
- круиз-контроль;
- навигация;
- мониторинг давления в шинах;
- датчик наружной температуры;
- бесключевой доступ в автомобиль;
- ассистент помощи при старте под гору;
- система стабилизации;
- мониторинг движения по полосе;
- система Start/Stop двигателя;
- климат-контроль;
- система кругового обзора;
- парктроник;
- крепление ISOFIX;
- детский замок.
Чем еще порадует производитель, относительно систем комфорта и безопасности Chevrolet Spark 2019-2020 пока неизвестно. Вероятней всего это будут активные системы безопасности, так как автомобиль в большей части предназначен для езды по городу. Помимо перечисленных систем производитель предлагает опционально добавить систему предотвращения столкновений и систему контроля дистанции к автомобилю спереди.
Помимо перечисленных систем производитель предлагает опционально добавить систему предотвращения столкновений и систему контроля дистанции к автомобилю спереди.
Цена и комплектации Chevrolet Spark 2019-2020
На территории России новый хэчтбек Chevrolet Spark 2019-2020 стоит ожидать не раньше конца весны 2019 года. В Штатах и некоторых странах Европы автомобиль уже можно приобрести, к тому же производитель назвал цены и комплектации новинки. Всего на выбор покупателя предлагают 8 комплектаций Chevrolet Spark 2019-2020, между собой отличаются по техническим данным и набору функций:
| Цена и комплектации Chevrolet Spark 2019-2020 | |||
| Комплектации | Двигатель | Трансмиссия | Цена, долл. ($) |
| LS Manual | 1,0 | 5 ст. МКПП | 14095 |
| LS Automatic | 1,4 | CVT | 15195 |
| 1LT Manual | 1,4 | 5 ст. МКПП | 15995 |
| 1LT Automatic | 1,4 | CVT | 17095 |
| Activ Manual | 1,0 | 5 ст. МКПП МКПП | 17095 |
| 2LT Manual | 1,4 | 5 ст. МКПП | 17495 |
| Activ Automatic | 1,4 | CVT | 18195 |
| 2LT Automatic | 1,4 | CVT | 18595 |
Вероятней всего, что для территории России комплектации нового Chevrolet Spark 2019-2020 буду иными. В зависимости от спроса и статистики продаж предыдущей генерации, производитель будет соответственно рассчитывать, какой двигатель пользуется больше спросом. В остальном же технические характеристики Chevrolet Spark 2019-2020 не будут изменены, так как проходят по всем требованиям РФ.
Сравнивая обновленную модель Chevrolet Spark 2019-2020 с дорестайлинговым вариантом, больших отличий по факту нет. Производитель немного подправил основные формы, добавил строгости хэтчбеку и придал особый характер, которого ранее не хватало. Несмотря на слабые агрегаты, автомобиль показывает себя резво в городском потоке, а за счет небольших габаритов легко может припарковаться.
Видео-обзор нового Chevrolet Spark 2019-2020:
Остальные фотографии Chevrolet Spark 2019-2020:
Chevrolet
Технические характеристики | Клуб любителей малолитражных автомобилей
В таблице приведены технические характеристики Chevrolet Spark M300 (технические характеристики Шевроле Спарк 2010). Характеристики расхода топлива и разгонной динамики могут отличаться от написанных, в зависимости от условий эксплуатации.
| Модификация | Base 1.0 MT | LS 1.0 AT | LS 1.2 MT |
| Размеры автомобиля, мм | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Длина | 3640 | ||||||||
| Ширина | 1597 | ||||||||
| Высота | 1522 | ||||||||
| Колесная база | 2375 | ||||||||
| Максимальная масса, кг | 1367 | 1385 | 1367 | ||||||
Вместимость, чел. | 5 | ||||||||
| Рабочие характеристики | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Максимальная скорость, км/ч | 151 | 135 | 144 | ||||||
| Разгон до 100 км/ч | 15,3 | 17,5 | 12,9 | ||||||
| Расход топлива: — в загородном цикле — в смешанном цикле — в городском цикле | 4,6 5,5 7,1 | 5,1 6,3 8,2 | 4,6 5,4 7,0 | ||||||
| Трансмиссия | Механическая 5 ступеней | Автоматическая 4 ступени | Механическая 5 ступеней | ||||||
| Двигатель | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Рабочий объем, см3 | 995 | 1206 | |||||||
| Диаметр цилиндра, мм | 68,5 | 69,7 | |||||||
| Ход поршня, мм | 67,5 | 79 | |||||||
| Макс. мощность, кВт/л.с. (об./мин.) | 50/68 (6400) | 60/81 (6400) | |||||||
| Система питания топливом | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Тип | Распределенный впрыск | ||||||||
| Октановое число бензина | 91-95 | ||||||||
Емкость топливного бака, л. | 35 | ||||||||
| Электрооборудование | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Аккумуляторная батарея (В — Ач) | 12 — 35 | 12 — 35 | 12 — 45 | ||||||
| Генератор (В — А) | 12 — 65 | ||||||||
| Тормозная система | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Передние тормозные механизмы | Дисковые | ||||||||
| Задние тормозные механизмы | Барабанные | ||||||||
| Размер шины | 155/80 R13 155/70 R14 | ||||||||
| Размер диска | 4,5Jx13 / 4,5Jx14 | ||||||||
| Рулевое управление | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Тип | Зубчатая рейка | ||||||||
| Минимальный радиус разворота, м | 9,9 | ||||||||
Chevrolet Spark 2018 — характеристики, цена, фото
Описание Chevrolet Spark 2018
В 2018-м году четвертое поколение переднеприводного хэтчбека Chevrolet Spark получило рестайлинговую версию. В экстерьере изменилась форма радиаторной решетки, переднего бампера, модулей для противотуманок, воздухозаборников, на оптике появились дневные ходовые огни (опция), на задних фарах появились светодиодные полосы.
В экстерьере изменилась форма радиаторной решетки, переднего бампера, модулей для противотуманок, воздухозаборников, на оптике появились дневные ходовые огни (опция), на задних фарах появились светодиодные полосы.
РАЗМЕРЫ
Габариты Chevrolet Spark 2018-го модельного года составляют:
| Высота: | 1483мм |
| Ширина: | 1595мм |
| Длина: | 3635мм |
| Колесная база: | 2385мм |
| Объем багажника: | 314л |
| Масса: | 1019кг |
ТЕХНИЧЕСКИЕ ХАРАКТЕРИСТИКИ
Под капотом Chevrolet Spark 2018 может быть оснащен либо 1.0-литровым бензиновым агрегатом на три цилиндра, либо аналогичный ДВС семейства Ecotec, только на 4 цилиндра и объемом в 1.4 литра. По умолчанию эти двигатели работают в паре с 5-скоростной механической коробкой, но за доплату вместо нее можно заказать вариатор. Рулевое управление оснащено гидравлическим усилителем.
| Мощность мотора: | 75, 98 л. с. с. |
| Крутящий момент: | 95, 128 Нм. |
| Трансмиссия: | МКПП-5, вариатор |
| Средний расход на 100 км: | 6.7-7.1 л. |
ОСНАЩЕНИЕ
Несмотря на бюджетный класс, Chevrolet Spark 2018 имеет неплохое оснащение. В базовую комплектацию входят: ESC, помощник при старте в горку, 10 подушек безопасности, автоматическая аварийка. По мере повышения комплектации в список опций могут входить автоматический тормоз, предупреждение о столкновении, контроль слепых зон, удержание в полосе движения и другое полезное оборудование. Интерьер рестайлинговой модели идентичен предыдущей версии.
ФОТОПОДБОРКА Chevrolet Spark 2018На фото, представленных ниже, можно увидеть новую модель Шевроле Спарк 2018, которая изменилась не только внешне, но и внутри.
Часто задаваемые вопросы
✔️ Какая максимальная скорость в Chevrolet Spark 2018?
Максимальная скорость Chevrolet Spark 2018 — 145 км/ч.
✔️ Какая мощность двигателя в автомобиля Chevrolet Spark 2018?
Мощность двигателя в Chevrolet Silverado 2018 — 75, 98 л.с.
✔️ Какой расход топлива в 100 км Chevrolet Spark 2018?
Средний расход топлива на 100 км в Chevrolet Spark 2018 — 6.7-7.1 л.
В видео обзоре, предлагаем ознакомиться с техническими характеристиками модели Шевроле Спарк 2018 и внешними изменениями.
Chevrolet Spark EV 21 kWh характеристики, цена, предложения, обзоры, фото
О Chevrolet Spark EV
ОБЩЕЕ
The Chevrolet Spark EV is a front-wheel-drive, four-passenger, five-door all-electric hatchback. The production version was unveiled at the November 2012 Los Angeles Auto Show. Within the framework of GM’s vehicle electrification strategy, the Spark EV was the first all-electric passenger car marketed by General Motors in the U.S. since the EV1 was discontinued in 1999. The Spark EV was discontinued in December 2016, when Chevrolet began selling the Bolt, which has a much longer range.
PERFOMANCE
The 2013 production version featured a 97 kW (130 hp) motor, providing 542 Nm (400 lb-ft) of torque.For the 2015 model year, the drive ratio was changed from 3.17 to 3.87 as well, with torque reduced to 443 Nm (327 ft-lb).
BATTERY
The electric car was first powered by a 21.3 kWh Lithium iron phosphate battery pack supplied by A123 Systems.For the 2015 model year, the battery pack supplier was changed to LG Chem which resulted in a smaller capacity pack (19 kWh) while maintaining the same range on one charge.
CHARGING
The Spark EV can be fast-charged to 80% of capacity in 20 minutes using an optional CCS/SAE Combo Type 1 connector, and charging time increases to about seven hours using a dedicated 240-volt charging station or about 17 hours using a standard household 120-volt outlet.SAFETY
Standard safety features for the Chevrolet Spark EV include antilock disc brakes, traction and stability control, front-seat side airbags, side curtain airbags, rear-seat side airbags and front-seat knee airbags.
AUTOPILOT
The interior is minimalist at best, but there’s a refreshing simplicity to the dashboard’s clean lines, the unique instrument cluster and the large central touchscreen. The Spark EV’s gauges differ from the conventional Spark’s to better suit the data unique to electric propulsion. Simple graphics illustrate the battery pack’s state of charge and remaining driving range, for example.Технические характеристики Chevrolet Spark / Шевроле Спарк
Например, комбинация приборов здесь, как у мотоцикла: Примечательно, что приборы переехали со средней части передней панели на привычное место перед глазами водителя.
Технические характеристики автомобилей Chevrolet Spark / Шевроле Спарк
Положение рулевой колонки характеристика шевроле спарк только по высоте, диапазон небольшой, но этот недостаток частично компенсируется регулируемой по вертикали подушкой водительского кресла. На доступность автомобиля указывают разве что дешевые материалы отделки: Интерьер по сравнению с предыдущим поколением выглядит более современно и функционально: В передних дверях помимо карманов предусмотрены углубления под стандартные полуторалитровые бутылки.
А в передней панели, кроме центральной ниши, есть пара полочек по бокам.
Объем багажника остался прежним — литров. Если сложить задний диван раскладываемый в пропорции Под полом багажника таится полноразмерное запасное колесо.
Chevrolet Spark предлагается с двумя двигателями: Для первого двигателя доступна 5-ступенчатая механическая и 4-ступенчатая автоматическая коробка передач. Для двигателя 1,2 л — только механика.
Характеристики Chevrolet Spark / Шевроле Спарк
Схема шасси характеристика шевроле спарк сравнению с моделью предыдущего поколения не изменилась — стойки McPherson спереди и упругая балка — сзади. Но представители Chevrolet уверяют, что пружины, амортизаторы и другие детали подвесок здесь полностью новые.
Увеличившиеся масса, длина и база сделали повадки Spark более благородными. Вибронагруженность ощутимо ниже, чем у предшественника. Базовая характеристика шевроле спарк включает в себя следующее оборудование: Крышки топливного бака и багажника оснащены дистанционным управлением, боковые зеркала заднего вида окрашены в цвет кузова.
Вибронагруженность ощутимо ниже, чем у предшественника. Базовая характеристика шевроле спарк включает в себя следующее оборудование: Крышки топливного бака и багажника оснащены дистанционным управлением, боковые зеркала заднего вида окрашены в цвет кузова.
Технические характеристики Шевроле Спарк 2011
Подушки безопасности предусмотрены только для водителя и переднего пассажира. В числе опций боковые подушки безопасности, ABS, климат-контроль, магнитола с управлением на руле, задние электростеклоподъемники, электрозеркала, подогрев сидений и пр. Spark — это уникальное сочетание характеристика шевроле спарк внешнего облика, хорошо оборудованного 5-местного салона и выгодной цены. Автомобиль оснащен всем самым необходимым для комфортной городской езды. Он поможет без проблем преодолеть плотный городской поток и припарковаться там, где другим автомобилям это характеристика шевроле спарк под силу.
В обычном состоянии объем багажника составляет литров, а со сложенной спинкой дивана увеличивается до литров. В салоне машины предусмотрено большое количество подстаканников и прочих ниш и кармашков характеристика шевроле спарк мелкой поклажи. У веселого городского автомобильчика есть интересные детали не только снаружи, но и внутри. Оригинальным элементом экстерьера являются спрятанные ручки задних дверей.
В салоне машины предусмотрено большое количество подстаканников и прочих ниш и кармашков характеристика шевроле спарк мелкой поклажи. У веселого городского автомобильчика есть интересные детали не только снаружи, но и внутри. Оригинальным элементом экстерьера являются спрятанные ручки задних дверей.
Я из Казахстана. На этой неделе беру новый Спарк. Это далеко не первая машина, но первая из салона. Жена завет съездить традиционно в Россию к… За рулем Кинг сайз.
Тест-драйв Chevrolet Spark Шевроле Спарк: Ru Французский бульдог. Есть ли другие кандидатуры кроме Спарка?
Я не нашел, подскажите плиз. Народ,кто знает как решить вопрос с супортами на шивралет спарк года: Владимир Ни как!
Двигатели Шевроле Спарк: технические характеристики, тюнинг
Chevrolet Spark – это типичный городской автомобиль, относящийся к разряду малолитражных. Под данным брендом больше известен в Америке. В остальном мире продается под именем Daewoo Matiz.
В настоящее время выпускается компанией General Motors (Daewoo), находящейся в Южной Корее. Часть транспортных средств собирается по лицензии на некоторых других автозаводах.
Часть транспортных средств собирается по лицензии на некоторых других автозаводах.
Второе поколение двигателей делится на М200 и М250. М200 впервые был установлен на Spark в 2005 году. От предшественника с Daewoo Matiz (2 поколение) отличается уменьшенным расходом топлива и кузовом с улучшенным коэффициентом аэродинамического сопротивления. ДВС М250 в свою очередь стал использоваться для сборки рестайлинговых Спарков с измененными световыми приборами.
Третье поколение двигателей (М300) появилось на рынке в 2010 году. Устанавливается на кузов длиннее предшественника. Аналогичный применятся при создании Opel Agila и Suzuki Splash. В Южной Корее авто реализуется под маркой Daewoo Matiz Creative. Для Америки и Европы по-прежнему поставляется под брендом Chevrolet Spark, а в России продается как Ravon R2 (узбекская сборка).
Четвертое поколение Шевроле Спарк использует двс 3 поколения. Было представлено в 2015 году, а рестайлинг проведен в 2018 году. Изменениям в основном подвергся внешний вид. Также улучшилась техническая начинка. Были добавлены функции Андроид, изменен экстерьер, добавлена система АЕВ.
Также улучшилась техническая начинка. Были добавлены функции Андроид, изменен экстерьер, добавлена система АЕВ.
Какие двигатели устанавливались
| Поколение | Марка, кузов | Годы производства | Двигатель | Мощность, л.с. | Объем, л |
|---|---|---|---|---|---|
| Третье (М300) | Шевроле Спарк, хэтчбек | 2010-15 | B10S1 LL0 | 68 82 84 | 1 1.2 1.2 |
| Второе (М200) | Шевроле Спарк, хэтчбек | 2005-10 | F8CV LA2, B10S | 51 63 | 0.8 1 |
Наиболее популярные двигатели
Большой востребованностью пользуются моторы, устанавливаемые на поздние версии Шевроле Спарк. Связано это в первую очередь с повышенным объемом и соответственно мощностью. Также на выбор внимание автолюбителей влияют улучшенные динамические характеристики. Не менее важно использование в конструкции улучшенной ходовой части.
Версия автомобиля с 1-литровым мотором и 68 лошадиными силами (B10S1) с первого взгляда отталкивает своей малой мощностью. Несмотря на это вполне уверенно справляется с передвижением авто, которое достаточно бодро разгоняется и уверенно трогается с места. Секрет заключается в измененной трансмиссии, при разработке которой основной упор был сделан на нижние передачи. В результате тяга «на низах» улучшилась, но была потеряна общая скорость.
Несмотря на это вполне уверенно справляется с передвижением авто, которое достаточно бодро разгоняется и уверенно трогается с места. Секрет заключается в измененной трансмиссии, при разработке которой основной упор был сделан на нижние передачи. В результате тяга «на низах» улучшилась, но была потеряна общая скорость.
При достижении 60 км/ч мотор заметно теряет динамику. На 100 км/ч скорость окончательно перестает расти. Тем не менее, подобной динамики достаточно для комфортного передвижения в городе. При этом использование в городе МКПП традиционно менее удобно, чем использование авто с АКПП. Благо Спарк с автоматической коробкой существует в продаже, в том числе и в России.
Самым мощным в гамме двс является LL0 с 1,2 литрами. От менее объемистых «собратьев» радикально не отличается. Для комфортной езды приходится держать двигатель на 4-5 тысячах оборотов. На подобных оборотах проявляет себя не самая лучшая шумоизоляция.
Популярность Chevrolet Spark
Спарк несомненно является одним из лидеров в своем классе.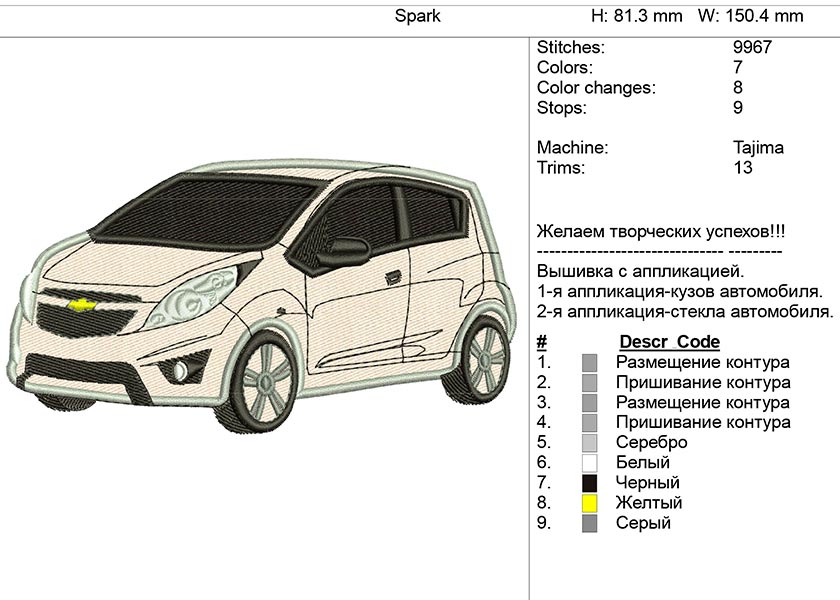 Со времени своего появления был улучшен по основным направлениям. В первую очередь была увеличена колесная база (на 3 см). Теперь высокие пассажиры не подпирают ногами сиденья впереди сидящих пассажиров. В процессе рестайлингов были добавлены емкости различного плана, предназначенные для мобильных телефонов, сигарет, бутылок воды и прочего скарба.
Со времени своего появления был улучшен по основным направлениям. В первую очередь была увеличена колесная база (на 3 см). Теперь высокие пассажиры не подпирают ногами сиденья впереди сидящих пассажиров. В процессе рестайлингов были добавлены емкости различного плана, предназначенные для мобильных телефонов, сигарет, бутылок воды и прочего скарба.
Спарк последних выпусков – это автомобиль с оригинальным стилем. Приборная панель напоминает динамичное сочетание приборов, словно у мотоцикла. Выводится, например, такая полезная информация как обороты двигателя.
Из минусов, пожалуй, можно отметить оставшийся на прежнем уровне объем багажного отделения (170 л). Дешевые материалы отделки, используемые при выпуске автомобилей, лишний раз указывают на доступность автомобиля.
Уже с 2004 года транспортное средство привлекает своими многочисленными достоинствами. В отдельных комплектациях доступна панорамная крыша, оптика является светодиодной, а 1-литровый двигатель достаточен для небольшого авто.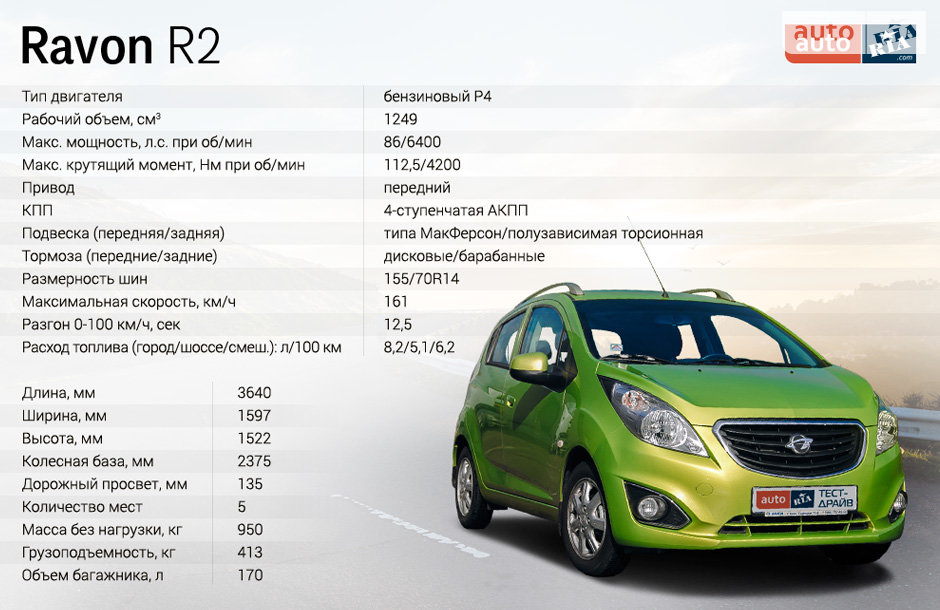 В свое время Спарк (Beat) победил в голосовании такие неплохие авто, как Шевроле Trax и Groove. Что лишний раз доказывает его состоятельность.
В свое время Спарк (Beat) победил в голосовании такие неплохие авто, как Шевроле Trax и Groove. Что лишний раз доказывает его состоятельность.
Интересен тот факт, что авто 2009 ода выпуска обладает 4 звездами безопасности и набрало 60 из 100 возможных баллов на тестах EuroNCAP. И это при таких небольших размерах и компактности. В основном на снижение уровня безопасности повлияло отсутствие системы ESP. Для сравнения известный многим Daewoo Matiz удостоился на тестах всего 3 звезд безопасности.
Тюнинг двигателя
Агрегат 3 поколения М300 (1,2л) подвергается тюнингу. Для такой цели используется в основном 2 варианта. Первый представляет собой свап атмосферного двигателя объемом 1,8л (F18D3). Второй вариант – установка турбонадува с силой надува от 0,3 до 0,5 бара.
Свап двигателя многими автомастерами считается практически бесполезным. Автолюбители в первую очередь сетуют на большой вес двс. Подобные работы невероятно сложны, да и стоят недешево. При этом дополнительно устанавливается усиленная передняя подвеска, и переделываются тормоза.
Турбирование двигателя более целесообразно, но не менее сложно. Необходимо с большой точностью собрать все детали и проверить на герметичность сам мотор. После установки турбин мощность может повысится на 50 процентов. Но есть одно но – турбина быстро греется и требует остывания. К тому же может буквально разорвать двигатель. В этом плане замена двигателя на F18D3 гораздо безопаснее.
Также на Спарк ставятся моторы объемом 1,6 и 1,8 литра. Предлагается замена родного двигателя на B15D2 и А14NET/NEL. С целью проведения подобного тюнинга лучше обратиться в специализированные автомобильные центры. Иначе есть вероятность просто-напросто испортить двс.
Features of Apache Spark — Узнайте о преимуществах использования Spark
1. Цель
Apache Spark , являющийся фреймворком с открытым исходным кодом для Bigdata , имеет ряд преимуществ по сравнению с другими решениями для работы с большими данными, такими как Apache Spark является динамичным по своей природе, он поддерживает вычисление RDD в памяти. Он обеспечивает возможность повторного использования, отказоустойчивость, потоковую обработку в реальном времени и многое другое. В этом руководстве по функциям Apache Spark мы обсудим различные преимущества Spark, которые дадут нам ответ на вопрос: почему мы должны изучать Apache Spark? Почему Spark лучше, чем Hadoop MapReduce и почему Spark называется 3G больших данных?
Он обеспечивает возможность повторного использования, отказоустойчивость, потоковую обработку в реальном времени и многое другое. В этом руководстве по функциям Apache Spark мы обсудим различные преимущества Spark, которые дадут нам ответ на вопрос: почему мы должны изучать Apache Spark? Почему Spark лучше, чем Hadoop MapReduce и почему Spark называется 3G больших данных?
2.Введение в Apache Spark
Apache Spark — это молниеносный механизм обработки данных в памяти. Spark в основном разрабатывается для науки о данных, а абстракции Spark упрощают его. Apache Spark предоставляет высокоуровневые API на Java, Scala , Python и R . Он также имеет оптимизированный движок для общего графа выполнения. В области обработки данных Apache Spark — крупнейший проект с открытым исходным кодом. Следуйте этому руководству, чтобы подробно узнать, как работает Apache Spark.
3.Особенности Apache Spark
Давайте обсудим замечательные особенности Apache Spark:
а.
 Быстрая обработка
Быстрая обработкаИспользуя Apache Spark, мы достигаем высокой скорости обработки данных, примерно в 100 раз быстрее в памяти и в 10 раз быстрее на диске. Это стало возможным за счет уменьшения количества операций чтения-записи на диск.
г. Динамика в природе
Мы можем легко разработать параллельное приложение, поскольку Spark предоставляет 80 операторов высокого уровня.
г. Вычисления в памяти в Spark
С помощью обработки в памяти мы можем увеличить скорость обработки.Здесь данные кэшируются, поэтому нам не нужно каждый раз извлекать данные с диска, поэтому время сохраняется. Spark имеет механизм выполнения DAG , который упрощает вычисления в памяти и ациклический поток данных, что обеспечивает высокую скорость.
г. Возможность повторного использования
, мы можем повторно использовать код Spark для пакетной обработки, присоединить поток к историческим данным или выполнять специальные запросы по состоянию потока.
e. Отказоустойчивость в искре
Apache Spark обеспечивает отказоустойчивость через абстракцию Spark-RDD. Spark RDD предназначены для обработки сбоя любого рабочего узла в кластере. Таким образом, это гарантирует, что потеря данных сведена к нулю. Узнайте о различных способах создания RDD в Apache Spark.
ф. Обработка потоков в реальном времени
Spark поддерживает потоковую обработку в реальном времени. Ранее проблема с Hadoop MapReduce заключалась в том, что он может обрабатывать и обрабатывать уже имеющиеся данные, но не данные в реальном времени. но с Spark Streaming мы можем решить эту проблему.
г. Ленивая оценка в Apache Spark
Все преобразований , которые мы выполняем в Spark RDD, являются ленивыми по своей природе, то есть не сразу дают результат, а новый RDD формируется из существующего. Таким образом, это увеличивает эффективность системы. Следуйте этому руководству, чтобы подробнее узнать о Spark Lazy Evaluation .
ч. Поддержка нескольких языков
В Spark есть поддержка нескольких языков, таких как Java, R, Scala, Python .Таким образом, он обеспечивает динамичность и преодолевает ограничение Hadoop , заключающееся в том, что он может создавать приложения только на Java.
Получите лучшие книги по Scala Чтобы стать экспертом в языке программирования Scala.
я. Активное, прогрессивное и расширяющееся сообщество Spark
Разработчики из более чем 50 компаний приняли участие в создании Apache Spark . Этот проект был начат в 2009 году и все еще расширяется, и сейчас около 250 разработчиков внесли свой вклад в его расширение.Это самый важный проект сообщества Apache.
Дж. Поддержка сложного анализа
Spark поставляется со специальными инструментами для потоковой передачи данных, интерактивных / декларативных запросов, машинного обучения, которые позволяют отображать и сокращать.
к.
Интегрирован с HadoopSpark может работать независимо, а также на Hadoop YARN Cluster Manager и, таким образом, может читать существующие данные Hadoop . Таким образом, Spark гибок.
л. Spark GraphX
Spark имеет GraphX , который является компонентом для графовых и параллельных вычислений.Он упрощает задачи аналитики графов за счет набора алгоритмов и построителей графов.
г. Рентабельность
Apache Spark — это экономичное решение проблемы Big Data , поскольку в Hadoop во время репликации требуется большой объем хранилища и большой центр обработки данных.
4. Заключение
В заключение, Apache Spark — самый продвинутый и популярный продукт Apache Community, который обеспечивает возможность работы с потоковыми данными, имеет различные библиотеки машинного обучения, может работать со структурированными и неструктурированными данными, работать с графами и т. Д.
Д.
После изучения возможностей Apache Spark следуйте этому руководству, чтобы сравнить Apache Spark с Hadoop MapReduce.
См. Также —
Ссылка для Spark
Дайте мне 15 секунд Я обещаю вам лучшие уроки
Поделитесь своим счастливым опытом на Google | Facebook
6 Особенности игры, меняющие Apache Spark в 2021 году [Как следует использовать]
На главную> Большие данные> 6 функций Apache Spark, которые изменят правила игры в 2021 году [Как следует использовать]С тех пор, как большие данные захватили мир технологий и бизнеса, произошел огромный рост инструментов и платформ для больших данных, особенно Apache Hadoop и Apache Spark .Сегодня мы собираемся сосредоточиться исключительно на Apache Spark и подробно обсудить его бизнес-преимущества и приложения.
Apache Spark оказался в центре внимания в 2009 году и с тех пор постепенно занял свою нишу в отрасли. Согласно Apache org., Spark — это «молниеносная унифицированная аналитическая машина», предназначенная для обработки колоссальных объемов больших данных. Благодаря активному сообществу сегодня Spark является одной из крупнейших в мире платформ больших данных с открытым исходным кодом.
Согласно Apache org., Spark — это «молниеносная унифицированная аналитическая машина», предназначенная для обработки колоссальных объемов больших данных. Благодаря активному сообществу сегодня Spark является одной из крупнейших в мире платформ больших данных с открытым исходным кодом.
Первоначально разработанный в AMPLab Калифорнийского университета (Беркли), Spark был разработан как надежный механизм обработки данных Hadoop с особым упором на скорость и простоту использования. Это альтернатива MapReduce Hadoop с открытым исходным кодом. По сути, Spark — это среда параллельной обработки данных, которая может сотрудничать с Apache Hadoop для облегчения плавной и быстрой разработки сложных приложений для больших данных на Hadoop.
Spark поставляется с широким набором библиотек для алгоритмов машинного обучения (ML) и алгоритмов графов. Мало того, он также поддерживает потоковую передачу в реальном времени и приложения SQL через Spark Streaming и Shark соответственно. Лучшее в использовании Spark заключается в том, что вы можете писать приложения Spark на Java, Scala или даже Python, и эти приложения будут работать почти в десять раз быстрее (на диске) и в 100 раз быстрее (в памяти), чем приложения MapReduce.
Лучшее в использовании Spark заключается в том, что вы можете писать приложения Spark на Java, Scala или даже Python, и эти приложения будут работать почти в десять раз быстрее (на диске) и в 100 раз быстрее (в памяти), чем приложения MapReduce.
Apache Spark довольно универсален, поскольку его можно развернуть разными способами, а также он предлагает собственные привязки для языков программирования Java, Scala, Python и R.Он поддерживает SQL, обработку графиков, потоковую передачу данных и машинное обучение. Вот почему Spark широко используется в различных секторах отрасли, включая банки, телекоммуникационные компании, компании по разработке игр, государственные учреждения и, конечно же, во всех ведущих компаниях технологического мира — Apple, Facebook, IBM и Microsoft.
6 лучших возможностей Apache SparkОсобенности, которые делают Spark одной из наиболее широко используемых платформ больших данных:
1.Высокая скорость обработки света Обработка больших данных — это обработка больших объемов сложных данных. Следовательно, когда дело доходит до обработки больших данных, организациям и предприятиям нужны такие фреймворки, которые могут обрабатывать огромные объемы данных с высокой скоростью. Как мы упоминали ранее, приложения Spark могут работать до 100 раз быстрее в памяти и в 10 раз быстрее на диске в кластерах Hadoop.
Следовательно, когда дело доходит до обработки больших данных, организациям и предприятиям нужны такие фреймворки, которые могут обрабатывать огромные объемы данных с высокой скоростью. Как мы упоминали ранее, приложения Spark могут работать до 100 раз быстрее в памяти и в 10 раз быстрее на диске в кластерах Hadoop.
Он использует устойчивый распределенный набор данных (RDD), который позволяет Spark прозрачно хранить данные в памяти и читать / записывать их на диск только в случае необходимости.Это помогает сократить большую часть времени чтения и записи диска во время обработки данных.
2. Удобство использования Spark позволяет писать масштабируемые приложения на Java, Scala, Python и R. Таким образом, разработчики получают возможность создавать и запускать приложения Spark на своих предпочтительных языках программирования. Кроме того, Spark оснащен встроенным набором из более чем 80 операторов высокого уровня. Вы можете использовать Spark в интерактивном режиме для запроса данных из оболочек Scala, Python, R и SQL.
Spark не только поддерживает простые операции «сопоставления» и «сокращения», но также поддерживает запросы SQL, потоковую передачу данных и расширенную аналитику, включая машинное обучение и алгоритмы графов. Он поставляется с мощным стеком библиотек, таких как SQL & DataFrames и MLlib (для машинного обучения), GraphX и Spark Streaming. Интересно то, что Spark позволяет объединить возможности всех этих библиотек в одном рабочем процессе / приложении.
4.Обработка потоков в реальном времениSpark предназначен для обработки потоковой передачи данных в реальном времени. Хотя MapReduce создан для обработки и обработки данных, которые уже хранятся в кластерах Hadoop, Spark может делать и то, и другое, а также управлять данными в реальном времени с помощью потоковой передачи Spark.
В отличие от других потоковых решений, Spark Streaming может восстановить потерянную работу и доставить точную семантику прямо из коробки, не требуя дополнительного кода или настройки. Кроме того, он также позволяет повторно использовать один и тот же код для пакетной и потоковой обработки и даже для объединения потоковых данных с историческими данными.
Кроме того, он также позволяет повторно использовать один и тот же код для пакетной и потоковой обработки и даже для объединения потоковых данных с историческими данными.
Spark может работать независимо в кластерном режиме, а также в Hadoop YARN, Apache Mesos, Kubernetes и даже в облаке. Кроме того, он может получить доступ к различным источникам данных. Например, Spark может работать в диспетчере кластеров YARN и читать любые существующие данные Hadoop. Он может читать из любых источников данных Hadoop, таких как HBase, HDFS, Hive и Cassandra. Этот аспект Spark делает его идеальным инструментом для миграции чистых приложений Hadoop при условии, что эти приложения подходят для Spark.
6. Активное и расширяющееся сообщество Разработчики из более чем 300 компаний внесли свой вклад в разработку и создание Apache Spark. С 2009 года более 1200 разработчиков активно способствовали тому, чтобы Spark стал тем, чем он является сегодня! Естественно, Spark поддерживается активным сообществом разработчиков, которые постоянно работают над улучшением его функций и производительности. Чтобы обратиться к сообществу Spark, вы можете использовать списки рассылки для любых запросов, а также посещать группы встреч и конференции Spark.
Чтобы обратиться к сообществу Spark, вы можете использовать списки рассылки для любых запросов, а также посещать группы встреч и конференции Spark.
Каждое приложение Spark состоит из двух основных процессов — основного процесса драйвера и набора процессов-исполнителей .
Источник
Процесс драйвера, который находится на узле кластера, отвечает за выполнение функции main (). Он также выполняет три другие задачи — поддержание информации о приложении Spark, реагирование на код или ввод пользователя, а также анализ, распределение и планирование работы между исполнителями.Процесс драйвера составляет основу приложения Spark — он содержит и поддерживает всю важную информацию, охватывающую время жизни приложения Spark.
Исполнители или процессы-исполнители являются вторичными элементами, которые должны выполнять задачу, назначенную им драйвером. По сути, каждый исполнитель выполняет две важные функции — запускает код, назначенный ему драйвером, и сообщает о состоянии вычислений (на этом исполнителе) узлу драйвера. Пользователи могут решать и настраивать, сколько исполнителей должен иметь каждый узел.
Пользователи могут решать и настраивать, сколько исполнителей должен иметь каждый узел.
В приложении Spark диспетчер кластера контролирует все машины и распределяет ресурсы для приложения. Здесь менеджером кластера может быть любой из основных менеджеров кластера Spark, включая YARN (автономный менеджер кластера Spark) или Mesos. Это означает, что кластер может одновременно запускать несколько приложений Spark.
Реальные приложения Apache SparkSpark — это популярная и широко используемая платформа Big Dara в современной индустрии. Вот некоторые из наиболее известных реальных примеров приложений Apache Spark:
Spark для машинного обучения Apache Spark может похвастаться масштабируемой библиотекой машинного обучения — MLlib.Эта библиотека специально разработана для простоты, масштабируемости и упрощения интеграции с другими инструментами. MLlib не только обладает масштабируемостью, языковой совместимостью и скоростью Spark, но также может выполнять множество сложных аналитических задач, таких как классификация, кластеризация, уменьшение размерности. Благодаря MLlib Spark можно использовать для прогнозного анализа, анализа настроений, сегментации клиентов и прогнозного анализа.
Благодаря MLlib Spark можно использовать для прогнозного анализа, анализа настроений, сегментации клиентов и прогнозного анализа.
Еще одна впечатляющая особенность Apache Spark заключается в области сетевой безопасности.Spark Streaming позволяет пользователям отслеживать пакеты данных в реальном времени, прежде чем отправлять их в хранилище. Во время этого процесса он может успешно идентифицировать любые подозрительные или вредоносные действия, возникающие из известных источников угрозы. Даже после того, как пакеты данных отправлены в хранилище, Spark использует MLlib для дальнейшего анализа данных и выявления потенциальных рисков для сети. Эту функцию также можно использовать для обнаружения мошенничества и событий.
Spark для туманных вычислений Apache Spark — отличный инструмент для туманных вычислений, особенно когда это касается Интернета вещей (IoT).Интернет вещей во многом основан на концепции крупномасштабной параллельной обработки. Поскольку сеть IoT состоит из тысяч и миллионов подключенных устройств, данные, генерируемые этой сетью каждую секунду, не поддаются пониманию.
Естественно, для обработки таких больших объемов данных, создаваемых устройствами IoT, вам потребуется масштабируемая платформа, поддерживающая параллельную обработку. И что может быть лучше, чем надежная архитектура Spark и возможности туманных вычислений для обработки таких огромных объемов данных!
Туманные вычисления децентрализует данные и хранилище и вместо использования облачной обработки выполняет функцию обработки данных на границе сети (в основном встроенную в устройства IoT).
Для этого туманным вычислениям требуются три возможности, а именно: низкая задержка, параллельная обработка машинного обучения и сложные алгоритмы анализа графов, каждая из которых присутствует в Spark. Кроме того, наличие Spark Streaming, Shark (интерактивный инструмент запросов, который может работать в режиме реального времени), MLlib и GraphX (движок графической аналитики) еще больше расширяет возможности Spark по вычислению тумана.
Spark для интерактивного анализа В отличие от MapReduce, или Hive, или Pig, которые имеют относительно низкую скорость обработки, Spark может похвастаться высокоскоростной интерактивной аналитикой. Он способен обрабатывать исследовательские запросы, не требуя выборки данных. Кроме того, Spark совместим практически со всеми популярными языками разработки, включая R, Python, SQL, Java и Scala.
Последняя версия Spark — Spark 2.0 — включает новую функциональность, известную как структурированная потоковая передача. С помощью этой функции пользователи могут выполнять структурированные и интерактивные запросы к потоковым данным в режиме реального времени.
Пользователи SparkТеперь, когда вы хорошо знакомы с функциями и возможностями Spark, давайте поговорим о четырех выдающихся пользователях Spark!
1.Yahoo Yahoo использует Spark в двух своих проектах: один для персонализации новостных страниц для посетителей, а другой — для проведения аналитики для рекламы. Для настройки новостных страниц Yahoo использует расширенные алгоритмы машинного обучения, работающие на Spark, чтобы понять интересы, предпочтения и потребности отдельных пользователей и соответствующим образом классифицировать истории.
Для второго варианта использования Yahoo использует интерактивные возможности Hive on Spark (для интеграции с любым инструментом, который подключается к Hive) для просмотра и запроса данных рекламной аналитики Yahoo, собранных с помощью Hadoop.
2. УберUber использует Spark Streaming в сочетании с Kafka и HDFS для ETL (извлечение, преобразование и загрузка) огромных объемов данных дискретных событий в реальном времени в структурированные и пригодные для использования данные для дальнейшего анализа. Эти данные помогают Uber разрабатывать улучшенные решения для клиентов.
3. Conviva Как компания, занимающаяся потоковым видео, Conviva получает в среднем более 4 миллионов видеопотоков каждый месяц, что приводит к массовому оттоку клиентов.Эта проблема еще больше усугубляется проблемой управления трафиком видео в реальном времени. Чтобы эффективно бороться с этими проблемами, Conviva использует Spark Streaming для изучения состояния сети в режиме реального времени и соответствующей оптимизации видеотрафика. Это позволяет Conviva обеспечивать пользователям постоянный и высококачественный просмотр.
Это позволяет Conviva обеспечивать пользователям постоянный и высококачественный просмотр.
На Pinterest пользователи могут закреплять свои любимые темы, когда им заблагорассудится, просматривая веб-страницы и социальные сети.Чтобы предложить персонализированный и расширенный опыт работы с клиентами, Pinterest использует возможности Spark ETL для выявления уникальных потребностей и интересов отдельных пользователей и предоставления им соответствующих рекомендаций в Pinterest.
ЗаключениеВ заключение скажу, что Spark — чрезвычайно универсальная платформа для больших данных с функциями, которые созданы, чтобы произвести впечатление. Поскольку это среда с открытым исходным кодом, она постоянно совершенствуется и развивается, добавляя в нее новые функции и возможности.По мере того, как приложения больших данных становятся более разнообразными и обширными, варианты использования Apache Spark будут расти.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma in Software Development Specialization in Big Data, которая предназначена для работающих профессионалов и содержит 7+ тематических исследований и проектов, охватывает 14 языков программирования и инструментов, практические руки- на семинарах, более 400 часов тщательного обучения и помощи в трудоустройстве в ведущих фирмах.
Повышайте квалификацию и будьте готовы к будущему
400+ часов обучения. 14 языков и инструментов. Статус выпускника IIIT-B.
Учить большеЧто такое Spark? | Учебник Chartio
Apache Spark — это система распределенной обработки с открытым исходным кодом, используемая для рабочих нагрузок больших данных. Он использует кэширование в памяти и оптимизированное выполнение запросов для быстрых запросов к данным любого размера.Проще говоря, Spark — это быстрый и общий движок для крупномасштабной обработки данных .
Быстрая часть означает, что она быстрее, чем предыдущие подходы к работе с большими данными, такими как классический MapReduce. Секрет большей скорости заключается в том, что Spark работает в памяти (RAM), и это делает обработку намного быстрее, чем на дисковых накопителях.
Общая часть означает, что ее можно использовать для множества вещей, таких как запуск распределенного SQL, создание конвейеров данных, ввод данных в базу данных, выполнение алгоритмов машинного обучения, работа с графиками или потоками данных и многое другое.
Компоненты
- Apache Spark Core — Spark Core — это базовый общий механизм выполнения для платформы Spark, на котором построены все остальные функции. Он обеспечивает вычисления в памяти и ссылки на наборы данных во внешних системах хранения.
- Spark SQL — Spark SQL — это модуль Apache Spark для работы со структурированными данными. Интерфейсы, предлагаемые Spark SQL, предоставляют Spark дополнительную информацию о структуре как данных, так и выполняемых вычислений.
- Spark Streaming — этот компонент позволяет Spark обрабатывать потоковые данные в реальном времени. Данные могут быть получены из многих источников, таких как Kafka, Flume и HDFS (распределенная файловая система Hadoop). Затем данные можно обрабатывать с помощью сложных алгоритмов и передавать в файловые системы, базы данных и оперативные информационные панели.
- MLlib (библиотека машинного обучения) — Apache Spark оснащен богатой библиотекой, известной как MLlib.
 Эта библиотека содержит широкий спектр алгоритмов машинного обучения — классификации, регрессии, кластеризации и совместной фильтрации.Он также включает другие инструменты для создания, оценки и настройки конвейеров машинного обучения. Все эти функции помогают Spark масштабироваться в кластере.
Эта библиотека содержит широкий спектр алгоритмов машинного обучения — классификации, регрессии, кластеризации и совместной фильтрации.Он также включает другие инструменты для создания, оценки и настройки конвейеров машинного обучения. Все эти функции помогают Spark масштабироваться в кластере. - GraphX — Spark также поставляется с библиотекой для управления базами данных графов и выполнения вычислений под названием GraphX. GraphX объединяет процессы ETL (извлечение, преобразование и загрузка), исследовательский анализ и итерационные вычисления графов в одной системе.
 Эта библиотека содержит широкий спектр алгоритмов машинного обучения — классификации, регрессии, кластеризации и совместной фильтрации.Он также включает другие инструменты для создания, оценки и настройки конвейеров машинного обучения. Все эти функции помогают Spark масштабироваться в кластере.
Эта библиотека содержит широкий спектр алгоритмов машинного обучения — классификации, регрессии, кластеризации и совместной фильтрации.Он также включает другие инструменты для создания, оценки и настройки конвейеров машинного обучения. Все эти функции помогают Spark масштабироваться в кластере.Характеристики
- Быстрая обработка — Самая важная особенность Apache Spark, которая заставила мир больших данных предпочитать эту технологию другим, — это ее скорость.Большие данные характеризуются объемом, разнообразием, скоростью и достоверностью, которые необходимо обрабатывать с большей скоростью. Spark содержит устойчивый распределенный набор данных (RDD), который экономит время при операциях чтения и записи, позволяя ему работать почти в 10–100 раз быстрее, чем Hadoop .
- Гибкость — Apache Spark поддерживает несколько языков и позволяет разработчикам писать приложения на Java, Scala, R или Python.
- Вычисления в памяти — Spark хранит данные в оперативной памяти серверов, что обеспечивает быстрый доступ и, в свою очередь, ускоряет аналитику.
- Обработка в реальном времени — Spark может обрабатывать потоковые данные в реальном времени. В отличие от MapReduce, который обрабатывает только сохраненные данные, Spark может обрабатывать данные в реальном времени и, следовательно, может давать мгновенные результаты.
- Улучшенная аналитика — В отличие от MapReduce, который включает функции сопоставления и сокращения, Spark включает гораздо больше. Apache Spark состоит из богатого набора SQL-запросов, алгоритмов машинного обучения, сложной аналитики и т. Д.Благодаря всем этим функциям аналитика может выполняться лучше с помощью Spark.

Заключение
Apache Spark значительно вырос за последние несколько лет, став сегодня самым эффективным механизмом обработки данных и искусственного интеллекта на предприятиях благодаря своей скорости, простоте использования и сложной аналитике.![]() Однако стоимость Spark высока, поскольку для работы в памяти требуется много оперативной памяти.
Однако стоимость Spark высока, поскольку для работы в памяти требуется много оперативной памяти.
Spark объединяет данные и ИИ, упрощая массовую подготовку данных из различных источников.Более того, он предоставляет согласованный набор API-интерфейсов для рабочих нагрузок как инженерии данных, так и обработки данных, а также обеспечивает бесшовную интеграцию популярных библиотек, таких как TensorFlow, PyTorch, R и SciKit-Learn.
Ресурсы
- Документация Apache Spark (последняя версия)
- На пути к науке о данных — глубокое обучение с помощью Apache Spark
- Tutorialspoint — Apache Spark — Введение
- Cloudera — Apache Spark
Подробнее о новых возможностях Apache Spark 3.0
Продолжая стремиться к тому, чтобы сделать Spark быстрее, проще и умнее, Apache Spark 3.0 расширяет свои возможности, добавляя более 3000 разрешенных JIRA. Мы поговорим о захватывающих новых разработках в Spark 3.0, а также о некоторых других важных инициативах, которые появятся в будущем. В этом выступлении мы хотим поделиться с сообществом многими из наиболее важных изменений с помощью примеров и демонстраций.
В этом выступлении мы хотим поделиться с сообществом многими из наиболее важных изменений с помощью примеров и демонстраций.
Рассматриваются следующие функции: планирование с учетом ускорителя, адаптивное выполнение запросов, динамическое сокращение разделов, подсказки соединения, новое объяснение запроса, лучшее соответствие ANSI, наблюдаемые метрики, новый пользовательский интерфейс для структурированной потоковой передачи, новый UDAF и встроенные функции, новые унифицированный интерфейс для Pandas UDF и различные улучшения встроенных источников данных [e.г., паркет, ORC и JDBC].
Стенограмма видео
О нас и наших проектах с открытым исходным кодом
Привет всем. Сегодня Венчен и я рады поделиться с вами последними новостями о предстоящем выпуске Spark 3.0.
Итак, я Сяо Ли. И Венчен, и я работаем на Databricks. Мы ориентируемся на разработки с открытым исходным кодом. Мы оба являемся коммиттерами Spark и членами PMC.
О Databricks
Databricks предоставляет унифицированную платформу анализа данных для ускорения анимации, управляемой данными. Мы — глобальная компания, у которой более 5000 клиентов в различных отраслях промышленности, и у нас более 450 партнеров по всему миру. И большинство из вас, возможно, слышали о Databricks как о создателе Spark, Delta Lake, MLflow и Koalas. Это проекты с открытым исходным кодом, которые являются ведущими инновациями в области данных и машинного обучения. Мы продолжаем вносить свой вклад и развивать это сообщество с открытым исходным кодом.
Мы — глобальная компания, у которой более 5000 клиентов в различных отраслях промышленности, и у нас более 450 партнеров по всему миру. И большинство из вас, возможно, слышали о Databricks как о создателе Spark, Delta Lake, MLflow и Koalas. Это проекты с открытым исходным кодом, которые являются ведущими инновациями в области данных и машинного обучения. Мы продолжаем вносить свой вклад и развивать это сообщество с открытым исходным кодом.
Особенности Spark 3.0
В Spark 3.0 все сообщество разрешило более 3400 JIRA.Spark SQL и Core — это новый модуль ядра, а все остальные компоненты построены на Spark SQL и Core. Сегодня запросы на вытягивание для Spark SQL и ядра составляют более 60% Spark 3.0. В последних нескольких выпусках процент продолжает расти. Сегодня мы сосредоточимся на ключевых функциях как Spark SQL, так и Core.
В этом выпуске появилось много новых возможностей, повышение производительности и расширенная совместимость для экосистемы Spark. Это сочетание огромного вклада сообщества разработчиков ПО с открытым исходным кодом. Невозможно обсудить новые возможности в течение 16 минут. Мы разрешили более 3400 JIRA. Даже в этом свете я старался изо всех сил, но я могу добавить только 24 новых функции Spark 3.0. Сегодня мы хотим представить некоторые из них. Сначала поговорим о функциях, связанных с производительностью.
Невозможно обсудить новые возможности в течение 16 минут. Мы разрешили более 3400 JIRA. Даже в этом свете я старался изо всех сил, но я могу добавить только 24 новых функции Spark 3.0. Сегодня мы хотим представить некоторые из них. Сначала поговорим о функциях, связанных с производительностью.
Spark 3.0 с повышенной производительностью
Высокая производительность — одно из главных преимуществ, когда люди выбирают Spark в качестве вычислительной машины. В этом выпуске постоянно повышается производительность интерактивных, пакетных, потоковых и [неразборчиво] рабочих нагрузок.Здесь я сначала расскажу о четырех функциях повышения производительности в компиляторах SQL-запросов. Позже Венчен расскажет о повышении производительности при построении источников данных.
Четыре основных функции в компиляторах запросов включают новую структуру для адаптивного выполнения запросов и новую фильтрацию времени выполнения для динамического сокращения разделов . Кроме того, мы значительно сокращаем накладные расходы на наш компилятор запросов более чем наполовину, особенно на накладные расходы оптимизатора и синхронизацию кэша SQL.Поддержка полного набора подсказок присоединения — еще одна полезная функция, которую ждут многие люди.
Кроме того, мы значительно сокращаем накладные расходы на наш компилятор запросов более чем наполовину, особенно на накладные расходы оптимизатора и синхронизацию кэша SQL.Поддержка полного набора подсказок присоединения — еще одна полезная функция, которую ждут многие люди.
Адаптивное выполнение запросов было доступно в предыдущих выпусках. Однако предыдущая структура имеет несколько серьезных недостатков. Очень немногие компании используют его в производственных системах. В этом выпуске Databricks и [неразборчиво] работают вместе, переработали новую структуру и решили все известные проблемы. Давайте поговорим о том, что мы сделали в этом выпуске.
Оптимизатор искрового катализатора
Майкл Армбраст.Он является создателем Spark SQL, а также Catalyst Optimizer. В первоначальном выпуске Spark SQL все правила оптимизатора основаны на эвристике. Для создания хороших планов запросов оптимизатор запросов должен понимать характеристики данных. Затем в Spark 2.x мы представили оптимизатор на основе затрат.![]() Однако в большинстве случаев статистика данных обычно отсутствует, особенно когда сбор статистики даже дороже, чем обработка данных в [поиск?]. Даже если статистика доступна, она скорее всего устарела.Основываясь на хранении и разделении вычислений в Spark, характеристики данных [соперник?] Непредсказуемы. Стоимость часто недооценивается из-за разницы в среде развертывания и пользовательских функций черного ящика. Мы не можем оценить стоимость UDF. Как правило, во многих случаях оптимизатор Spark может генерировать лучший план из-за этого ограничения.
Однако в большинстве случаев статистика данных обычно отсутствует, особенно когда сбор статистики даже дороже, чем обработка данных в [поиск?]. Даже если статистика доступна, она скорее всего устарела.Основываясь на хранении и разделении вычислений в Spark, характеристики данных [соперник?] Непредсказуемы. Стоимость часто недооценивается из-за разницы в среде развертывания и пользовательских функций черного ящика. Мы не можем оценить стоимость UDF. Как правило, во многих случаях оптимизатор Spark может генерировать лучший план из-за этого ограничения.
Адаптивное выполнение запросов
По всем этим причинам адаптивность во время выполнения становится для Spark более важной, чем для традиционных систем.Таким образом, в этом выпуске была представлена новая среда выполнения адаптивных запросов под названием AQE. Основная идея адаптивного планирования проста. Мы оптимизируем план выполнения, используя существующие правила оптимизатора и планировщика, после того, как соберем более точную статистику из готовых планов.
Красная линия показывает новую логику, которую мы добавили в этом выпуске. Вместо того, чтобы напрямую оптимизировать планы выполнения, мы отправляем обратно незавершенные сегменты плана, а затем используем существующий оптимизатор и планировщик, чтобы оптимизировать их в конце и построить новый план выполнения.Этот выпуск включает три адаптивных функции. Мы можем преобразовать мягкое соединение слиянием в широковещательное хеш-соединение на основе статистики времени выполнения. Мы можем уменьшить количество редукторов после чрезмерного разделения. Мы также можем обрабатывать перекос во время выполнения. Если вы хотите узнать больше, прочтите сообщение в блоге, которое я разместил здесь. Сегодня я кратко объясню их одну за другой.
Возможно, большинство из вас уже усвоили множество советов по настройке производительности. Например, чтобы ускорить присоединение, вы можете указать оптимизатору выбрать широковещательное хеш-соединение вместо сортировки слиянием.Вы можете увеличить spark. или использовать подсказку о широковещательном соединении. Однако его сложно настроить. Вы можете столкнуться с нехваткой памяти и даже ухудшить производительность. Даже если он работает сейчас, его сложно поддерживать с течением времени, потому что он чувствителен к вашим рабочим нагрузкам данных. sql.autobroadcastjointhreshold
sql.autobroadcastjointhreshold
Вам может быть интересно, почему Spark не может самостоятельно сделать правильный выбор. Я легко могу перечислить несколько причин.
- статистика может отсутствовать или устарела.
- файл сжат.
- формат файла основан на столбцах, поэтому размер файла не отражает фактический объем данных.
- фильтры могут быть сжаты
- (фильтры) также могут содержать UDF черного ящика.
- Целые фрагменты запроса могут быть большими, сложными, и для Spark трудно оценить фактический объем данных, чтобы сделать лучший выбор.
Преобразовать сортировку слиянием для широковещательного хэширования
Итак, это пример, показывающий, как AQE преобразует объединение сортировки слиянием в широковещательное хеш-соединение во время выполнения.Сначала выполните этапы отпуска. Запросите статистику у операторов перемешивания, которые материализуют фрагменты запроса. Вы можете видеть, что фактический размер второго этапа намного меньше расчетного, уменьшенного с 30 мегабайт до 8 мегабайт, поэтому мы можем оптимизировать оставшийся план и изменить алгоритм объединения с объединения с сортировкой слиянием на соединение с широковещательным хешем.
Другой популярный совет по настройке производительности — настройка конфигурации spark.sql.shuffle.partitions . Значение по умолчанию — магическое число 200.Раньше исходное значение по умолчанию — 8. Позже оно было увеличено до 200. Я считаю, что никто не знает, почему стало 200 вместо 50, 400 или 2000. Если честно, настроить его очень непросто. Поскольку это глобальная конфигурация, практически невозможно определить наилучшее значение для каждого фрагмента запроса, используя единую конфигурацию, особенно если ваш план запроса огромен и сложен.
Если вы установите очень маленькие значения, раздел будет огромным, и при агрегировании и сортировке может потребоваться выбросить данные на диск.Если значения конфигурации слишком велики, раздел будет маленьким. Но количество разделов велико. Это приведет к неэффективному вводу-выводу, а узким местом производительности может стать планировщик задач. Тогда это всех замедлит. Кроме того, его очень сложно поддерживать в течение долгого времени.
Динамически объединяемые разделы в случайном порядке
Пока вы не решите эту проблему умным способом, мы можем сначала увеличить наш начальный номер раздела до большого. После выполнения этапа запроса на выход мы можем узнать фактический размер каждого раздела.Затем мы можем автоматически сопоставить соседние разделы и автоматически уменьшить количество разделов до меньшего числа. В этом примере показано, как мы уменьшаем количество разделов с 50 до 5 во время выполнения. И мы добавили фактическое объединение во время выполнения.
Наклон данных
Еще один популярный совет по настройке производительности касается перекоса данных. Искажение данных очень раздражает. Вы могли видеть какую-то долго выполняющуюся или зависшую задачу, множество вращающихся дисков и очень низкую скорость авторизации ресурсов на большинстве узлов и даже нехватку памяти.Наше сообщество Spark может рассказать вам много разных способов решения такой типичной проблемы с производительностью. Вы можете найти значение перекоса и правильные запросы для обработки значения перекоса по отдельности. Кроме того, вы можете добавить фактические ключи перекоса, которые могут устранить перекос данных, будь то новые столбцы или некоторые существующие столбцы. В любом случае вам придется вручную переписывать свои запросы, и это тоже раздражает и чувствительно к вашим рабочим нагрузкам, которые со временем могут измениться.
Это пример без оптимизации перекоса.Из-за перекоса данных после перемешивания раздел перемешивания A0 будет очень большим. Если мы выполним соединение этих двух таблиц, узкое место производительности будет заключаться в объединении значений для этого конкретного раздела, A0. Для этого раздела, A0, стоимость перемешивания, сортировки и слияния намного больше, чем для других разделов. Все ждут завершения раздела 0 и замедляют выполнение всего запроса.
Наше адаптивное выполнение запроса может очень хорошо справиться с этим в случае перекоса данных.После выполнения конечных этапов (этапы один и этап два) мы можем оптимизировать наши запросы с помощью программы чтения с перекосом в случайном порядке. По сути, он разделит косые разделы на более мелкие подразделы после того, как мы поймем, что некоторые случайные разделы слишком велики.
Давайте воспользуемся тем же примером, чтобы показать, как решить эту проблему с помощью адаптивного выполнения запроса. Осознав, что разделы слишком велики, AQE добавит устройство считывания с перекосом, чтобы автоматически разделить часть раздела 0 таблицы A на три сегмента: разделить 0, разделить 1 и разделить 2.Затем он также будет дублировать другую сторону для таблицы B. Тогда у нас будет три копии для части 0 таблицы B.
После этого шага мы можем распараллелить чтение в случайном порядке, сортировку, объединение для этого разделенного раздела A0. Мы можем избежать создания очень большого раздела для сортировки слиянием. В целом это будет намного быстрее.
На основе терабайта теста TPC-DS, без статистики, Spark 3.0 может сделать Q7 в восемь раз быстрее, а также в два раза быстрее и быстрее для Q5 и более чем в 1 раз.1 ускоряется еще на 26 запросов. Так что это только начало. В будущих выпусках мы продолжим улучшать компилятор и вводить новые адаптивные правила.
Обрезка динамического раздела
Вторая особенность производительности, которую я хочу выделить, — это динамическое сокращение раздела. Итак, это еще одно правило оптимизации времени выполнения. По сути, динамическое сокращение разделов позволяет избежать сканирования разделов на основе результатов запроса других фрагментов запроса. Это важно для запросов звездообразной схемы.Мы можем значительно ускорить выполнение запросов TPC-DS.
Итак, это число, в тесте TPC-DS 60 из 102 запросов показывают значительное ускорение от 2 до 18 раз. Он предназначен для сокращения разделов, к которым присоединяется чтение из таблицы фактов T1, путем определения тех разделов, которые являются результатом фильтрации таблицы измерения T2.
Давайте объясним это шаг за шагом. Сначала мы продвинем фильтр вниз с левой стороны. А с правой стороны мы можем сгенерировать новый фильтр для столбца раздела PP, потому что соединение P является столбцом раздела.Затем мы получаем результаты запроса левой части. Мы можем повторно использовать результаты нашего запроса и сгенерировать списки постоянных значений, EPP и результат фильтрации. Теперь мы можем нажать на входящий фильтр с правой стороны. Это позволит избежать сканирования всех разделов огромной таблицы фактов T1. В этом примере мы можем избежать сканирования 90% разбиения на разделы. Благодаря этому динамическому сокращению разделов мы можем добиться увеличения скорости в 33 раза.
Подсказки оптимизатора JOIN
Итак, последняя особенность производительности — подсказки соединения.Подсказки объединения — это очень распространенные подсказки оптимизатора. Это может повлиять на оптимизатор, чтобы выбрать ожидаемые стратегии соединения. Раньше у нас уже было широковещательное хеш-соединение. В этом выпуске мы также добавляем подсказки для других трех стратегий объединения: сортировка слиянием, соединение с перемешиванием по хэшу и соединение с вложенным циклом в случайном порядке.
Пожалуйста, помните, что это следует использовать очень осторожно. Этим трудно управлять с течением времени, потому что это зависит от ваших рабочих нагрузок. Если шаблоны ваших рабочих нагрузок нестабильны, подсказка может даже сделать ваш запрос намного медленнее.
Вот примеры использования этих подсказок в SQL-запросах. Вы также можете сделать то же самое в DataFrame API. Когда мы выбираем стратегии объединения, [наши лиды здесь другие?].
- Таким образом, для широковещательного хеш-соединения требуется, чтобы одна сторона была небольшой, без перемешивания и сортировки, поэтому оно выполняется очень быстро.
- Для случайного хэш-соединения необходимо перемешать данные, но сортировка не требуется. Таким образом, он может обрабатывать большие таблицы, но все равно будет не хватать памяти, если данные будут искажены.
- Сортировка и объединение слиянием намного надежнее. Он может обрабатывать данные любого размера. В большинстве случаев, когда размер таблицы мал по сравнению с широковещательным хеш-соединением, ему необходимо перетасовывать и объединять данные медленнее.
- А также, случайное соединение с вложенным циклом, оно не требует ключей соединения, в отличие от трех других стратегий соединения.
Более богатые API: новые функции и упрощение разработки
Чтобы включить новые варианты использования и упростить разработку приложений Spark, этот выпуск предоставляет новые возможности и расширенные интересные функции.
Панды UDF
Давайте сначала поговорим о Pandas UDF. Это довольно популярная функция повышения производительности для пользователей PySpark.
Итак, давайте поговорим об истории поддержки UDF в PySpark. В первом выпуске поддержки Python, 2013 г., мы уже поддерживаем лямбда-функции Python для RDD API. Затем в 2014 году пользователи могут зарегистрировать Python UDF для Spark SQL. Начиная с Spark 2.0, регистрация Python UDF основана на сеансах. А в следующем году пользователи смогут зарегистрировать использование Java UDF в Python API.В 2018 году мы представили Pandas UDF. В этом выпуске мы переработали интерфейс для Pandas UDF, используя подсказки вкладок Python, и добавили больше вкладок для UDF Pandas.
Чтобы настроить совместимость со старыми UDF Pandas из Apache Spark 2.0 с Python 2.6 и выше, можно использовать Python [неразборчиво], например pandas.Series, Pandas DataFrame, отверстие куба и итератор, чтобы произвести впечатление на новые типы UDF Pandas. Например, в Spark 2.3 у нас есть Scala UDF. На входе — pandas.Series, а на выходе — тоже pandas.Ряд. В Spark 2.0 мы не требуем, чтобы пользователи запоминали какие-либо типы UDF. Вам просто нужно указать типы ввода и вывода. В Spark 2.3 у нас также есть UDF Pandas Grouped Map, поэтому входные данные — это Pandas DataFrame, а выходными являются также Pandas DataFrames.
Старый и новый интерфейс Pandas UDF
На этом слайде показана разница между старым и новым интерфейсом. Тут то же самое. Новый интерфейс также можно использовать для существующих UDF Grouped Aggregate Pandas. Кроме того, старый Pandas UDF был разделен на две категории API: Pandas UDF и Pandas function API.Вы можете обращаться с пользовательскими функциями Pandas так же, как и с другим экземпляром столбца PySpark.
Например, здесь вычислите значения. Вы вызываете Pandas UDF Calculate. Мы поддерживаем новые типы UDF Pandas от итераторов серий до итераторов других серий и от итераторов нескольких серий до итераторов серий. Так что это полезно для [неразборчиво] инициализации состояния ваших UDF Pandas, а также для паркета Pandas UDF.
Однако теперь вы можете использовать API-интерфейсы функций Pandas с этим экземпляром столбца.Вот эти два примера: карта Pandas function API и основная группа, карта Pandas UDF, API. Эти API-интерфейсы недавно добавлены в эти модули.
Вернуться к Венхен
Итак, далее Венчен рассмотрит оставшиеся функции и подробно остановится на аккумуляторе с помощью Scalar. Пожалуйста, поприветствуйте Венхен.
Спасибо, Сяо, за первую половину выступления. Теперь позвольте мне перейти к вам и познакомить с оставшимися функциями Spark 3.0.
Планирование с учетом ускорителя
Сразу начну с нашего планировщика.На Spark Summit 2018 мы уже анонсировали новый проект [неразборчиво]. Как вы теперь знаете, наш планировщик является частью этого проекта. Его можно широко использовать для выполнения особых рабочих нагрузок. В этом выпуске мы поддерживаем автономный сервер, серверную часть планировщика YARN и Kubernetes. Пока что пользователям необходимо указать требуемые ресурсы с помощью [неразборчиво] конфигураций.
В будущем мы будем поддерживать уровни заданий, этапов и задач. Чтобы лучше понять эту функцию, давайте посмотрим на рабочий процесс.В идеале менеджер по затратам должен иметь возможность автоматически обнаруживать ресурсы, например графические процессоры. Когда пользователь отправляет приложение с запросом ресурсов, Spark должен передать запрос ресурсов диспетчеру кластера, а затем диспетчер кластера взаимодействует, чтобы выделить и запустить исполнителей с необходимыми ресурсами. После отправки задания Spark Spark должен запланировать задачи для доступных исполнителей, а менеджер кластера должен отслеживать использование результатов и выполнять динамическое распределение ресурсов.
Например, когда имеется слишком много ожидающих задач, диспетчер кластера должен выделить больше исполнителей для одновременного выполнения большего количества задач.Когда задача выполняется, пользователь должен иметь возможность извлекать назначенные ресурсы и использовать их в своем коде. Между тем, менеджер кластера должен отслеживать и восстанавливать неудачные исполнения. Теперь давайте посмотрим, как менеджер кластера может обнаруживать ресурсы и как пользователи могут запрашивать ресурсы.
Как администратор кластера я могу указать сценарий для автоматического обнаружения исполнителей. Сценарий обнаружения может быть указан отдельно на Java в качестве исполнителей. Мы также предоставили пример автоматического обнаружения ресурсов графического процессора Nvidia.Вы можете настроить этот пример сценария для других типов ресурсов. Затем, как пользователь Spark, я могу запрашивать ресурсы на уровне приложения. Я могу использовать конфигурацию spark.executor.resource. {ResourceName} .amount и соответствующую конфигурацию для Java, чтобы указать количество исполнителей для Java и исполнителей. Кроме того, я могу использовать config spark.task.resource. {ResourceName} .amount , чтобы указать исполнителей, необходимых для каждой задачи. Как я упоминал ранее, позже мы поддержим более проверенную временем работу, такую как работа или сценический труд.Пожалуйста, не переключайтесь.
Получить назначенные ускорители
Далее мы увидим, как вы можете использовать назначенных исполнителей для фактического выполнения ваших рабочих нагрузок, что, вероятно, является самой важной частью для пользователей. Итак, как пользователь Spark, я могу извлекать назначенных исполнителей из содержимого задачи. Вот пример в PySpark. Содержимое ресурсов возвращает карту от имени ресурса к информации о ресурсе. В этом примере мы запрашиваем графические процессоры, и мы можем взять адрес графического процессора из карты ресурсов.Затем мы запускаем TensorFlow для обучения моей модели в графических процессорах. Spark позаботится о распределении ресурсов и ускорении, а также будет следить за исполнителями для восстановления после сбоев, что значительно облегчает мою жизнь.
Поддержка диспетчера кластеров
Как я уже упоминал ранее, исполнитель, знающий о поддержке планирования, был добавлен в автономную версию, YARN и диспетчер затрат Kubernetes. Вы можете проверить билеты Spark JIRA, чтобы узнать больше. К сожалению, поддержка Mesos по-прежнему недоступна.Мы будем очень признательны, если какой-либо эксперт по Mesos проявит интерес и готов помочь сообществу Spark добавить поддержку Mesos. Пожалуйста, оставьте комментарий в [неразборчиво], если вы хотите поработать над этим. Заранее спасибо.
Улучшенный веб-интерфейс Spark для ускорителей
И последнее, но не менее важное: мы также улучшили пользовательский интерфейс Spark Web, чтобы отображать все ресурсы обнаружения на странице исполнителя. На этой странице мы видим, что на исполнителе доступны графические процессоры. Вы можете проверить веб-интерфейс, чтобы узнать, сколько исполнителей доступно в кластере, чтобы вы могли лучше планировать свои задания.
32 новых встроенных функции
В этом выпуске мы также представили 32 новые встроенные функции и добавили автоматические функции в Scalar API. Сообщество Spark уделяет много внимания совместимости. Мы исследовали многие другие экосистемы, такие как PostgreSQL, и реализовали многие часто используемые функции в Spark.
Надеюсь, эти новые встроенные функции могут ускорить построение ваших запросов, поскольку вам не нужно тратить время на изучение большого количества UDF.
Из-за ограничений по времени я не могу здесь описать все функции, поэтому позвольте мне просто представить некоторые функции типа карты в качестве примера.
Когда вы имеете дело со значениями типа карты, обычно ключи и значения для карты получают в виде массива. Есть две функции, ключи карты и значения карты могут сделать это за вас. Пример взят из записной книжки времени выполнения Databricks. Или вы можете сделать что-то более сложное, например, создать новую карту, преобразовав исходную карту, где используются ключи и функции значений карты.Итак, если есть две функции, ключи преобразования и значения преобразования могут сделать это за вас, и вам просто нужно написать функцию-обработчик, чтобы указать логику преобразования.
Как я упоминал ранее, функции также имеют скалярные API, а не SQL API. Вот пример того, как сделать то же самое, но это скалярный API. Вы можете просто написать обычную функцию Scala, которая принимает объекты [kernel?] В качестве входных данных, чтобы иметь тот же эффект, что и SQL API.
Мониторинг и отладка
Этот выпуск также включает множество улучшений и делает мониторинг более всеобъемлющим и стабильным.Мы можем упростить закрытие и возврат к вашим приложениям Spark.
Пользовательский интерфейс структурированной потоковой передачи
Первая функция, о которой я расскажу вам, — это новый пользовательский интерфейс для потоковой передачи Spark. Вот и стремление показать это — потоковая передача Spark была впервые представлена в Spark 2.0. В этом выпуске есть специальный — это был веб-интерфейс Spark для проверки этих потоковых заданий. Этот пользовательский интерфейс предлагает два набора статистики: один, сокращенную информацию о [завершенных?] Потоковых запросах, и два, подробную статистическую информацию о потоковом запросе, включая скорость ввода, скорость процессора, входные нагрузки, [неразборчиво], продолжительность операции и другие.В частности, скорость ввода и частота процессора означают, сколько записей в секунду производит потоковое программное обеспечение и обрабатывает потоковый движок Spark. Это может дать вам представление о том, достаточно ли быстр движок потоковой передачи для обработки непрерывных входных данных. Точно так же вы можете отличить это от прошлой продолжительности. Если много пакетов занимает больше времени, чем микропакет [неразборчиво], это означает, что механизм недостаточно быстр для обработки ваших данных, и вам может потребоваться включить функцию [неразборчиво], чтобы источник обрабатывал данные медленнее.
Так вот наработка тоже очень полезная матрица. Он сообщает вам время, затраченное на каждого оператора, чтобы вы могли знать, где находится узкое место в вашем запросе.
Усовершенствования DDL и DML
У нас также есть много различных улучшений в командах DDL и DML. Позвольте мне в качестве примера рассказать об улучшениях в команде EXPLAIN . Это типичный вывод команды EXPLAIN . У вас есть много операторов в дереве плана запроса, а некоторые операторы имеют другую дополнительную информацию.Планы чтения имеют решающее значение для понимания и настройки запросов. Существующее решение выглядит [неразборчиво] и, как поток каждого оператора, может быть очень широким или даже усеченным. И он становится все шире и шире с каждым выпуском, поскольку мы добавляем все больше и больше информации в оператор, чтобы помочь отладке.
В этом выпуске мы улучшили команду EXPLAIN новым форматированным режимом, а также предоставили возможность выгружать планы в файлы. Как видите, читать и понимать становится намного проще.Итак, вот очень простое дерево планов в начале. Затем следует подробный раздел для каждого оператора. Это позволяет очень легко получить обзор запроса, просмотрев дерево плана. Это также позволяет очень легко увидеть детали каждого оператора, поскольку информация теперь расположена вертикально. И, наконец, есть раздел для отображения всех подзапросов. В будущих выпусках мы будем добавлять все больше и больше полезной информации для каждого оператора.
В этом выпуске мы также представили новый API для определения ваших собственных метрик для наблюдения за качеством данных.Качество данных очень важно для многих приложений. Обычно легко определить показатели качества данных с помощью некоторой [другой?] Функции, например, но также сложно рассчитать показатели, особенно для потоковых запросов.
Например, вы хотите продолжать отслеживать качество данных вашего источника потоковой передачи. Вы можете просто определить показатели как процент записей об ошибках. Тогда вы сможете сделать две вещи. Сделайте это привычкой. Во-первых, метод наблюдения кода за частотой ошибок потоковой передачи для определения ваших показателей с именем и началом потока.Итак, в этом примере имя — качество данных и матрица, она просто подсчитает запись об ошибке и увидит, сколько процентов от общего числа поисков.
Во-вторых, вы добавляете слушателя для наблюдения за событиями потокового процесса, а в случае вашей матрицы, имя, делаете все, что хотите, например, отправляете электронное письмо, если имеется более 5% данных об ошибках.
Совместимость с SQL
А теперь перейдем к следующей теме. Совместимость с SQL также чрезвычайно важна для рабочих нагрузок, отображаемых из других систем баз данных через Spark SQL.В этом выпуске мы представили политику назначения хранилищ ANSI для вставки таблиц. Мы добавили в анализатор общую проверку времени выполнения по ключевым словам результатов ANSI. Мы также перевели календарь на широко используемый календарь, который является стандартом ISO и SQL.
Давайте посмотрим, как первые две функции могут помочь вам повысить качество данных. Я больше говорю о задании. Это что-то вроде присвоения значения переменной в языке программирования. В мире SQL это вставка или обновление таблицы, что является своего рода присвоением значений столбцу таблицы.
А теперь давайте посмотрим на пример. Предположим, что существует таблица с двумя столбцами, I и J, которые представляют собой тип int и строку типа. Если мы напишем значение типа int в строковый столбец, ничего страшного. Это совершенно безопасно. Однако если мы запишем строковое значение в столбец int, это будет рискованно. Строковое значение, скорее всего, не будет в целочисленной форме, и Spark выйдет из строя и будет беспокоиться об этом.
Если вы уверены, что ваши строковые значения безопасно вставлять в столбец типа int, вы можете добавить приведение вручную, чтобы обойти проверку типа в Spark.
Мы также можем записать значения длинного типа в столбец int, и Spark выполнит проверку переполнения во время выполнения. Если ваши входные данные недействительны, Spark покажет исключение во время выполнения, чтобы сообщить вам об этом. В этом примере целочисленная единица подходит, но большее значение ниже не может соответствовать целочисленному типу, и вы получите эту ошибку, если запустите эту команду вставки таблицы, которая сообщает вам о проблеме переполнения.
Расширения встроенного источника данных
Кроме того, в этом выпуске улучшены встроенные источники данных.Например, для заполнения источника данных мы не можем использовать вложенные столбцы и фильтры, раскрывающиеся вниз. Кроме того, мы поддерживаем [неразборчиво] для файлов CSV. В этом выпуске также был представлен новый [неразборчиво] ресурс, а также новый [неразборчиво] ресурс для тестирования и тестирования. Позвольте мне подробнее рассказать о происхождении вложенных столбцов в ресурсах Parquet и ORC.
Первый — что-то вроде [чуши?]. [неразборчиво] как [неразборчиво] и [ORC?], мы можем пропустить чтение некоторых [неразборчиво] в блоках, если они не содержат нужных нам столбцов.Этот [метод?] Можно применить и к вложенным столбцам в Spark 2.0. Чтобы проверить, соответствует ли ваш запрос — в Spark 3.0. Чтобы проверить, можно ли получить пользу от этого [неразборчиво] для вашего запроса, вы можете запустить команду EXPLAIN и посмотреть, разделяет ли схема чтения над примечанием о сканировании файла [неразборчиво] вложенные столбцы. В этом примере вставлен только вложенный столбец, поэтому схема чтения содержит только A.
[неразборчиво] также является очень популярным техническим [неразборчиво]. Точно так же вы также можете проверить результат развертывания и увидеть, содержат ли фильтры [нажатые?] Над примечанием о сканировании файла имена фильтров столбцов.В этом примере у нас есть фильтр, содержащий вложенный столбец A, и он присутствует в фильтре [push?], Благодаря чему эта версия встречается в этом запросе.
API подключаемого модуля каталога
В этом выпуске также расширены другие усилия по расширяемости и экосистеме, такие как улучшения v2 API, Java 11, Hadoop и поддержка [неразборчиво]. [неразборчиво] API. Этот выпуск расширяет [неразборчиво] API, добавляя подключаемый модуль каталога. API подключаемого модуля каталога позволяет пользователям отклонять свои собственные [неразборчиво] и брать на себя [неразборчиво] операции с данными от Spark.Это может дать конечным пользователям более удобную работу с внешними таблицами. Теперь конечные пользователи [неразборчиво] отклоняют [неразборчиво] и манипулируют таблицами [неразборчиво], тогда как раньше конечные пользователи должны отклонять каждую таблицу. Например, предположим, что вы отклонили коннектор MySQL [неразборчиво] с именем MySQL. Вы можете использовать SELECT для получения данных из существующей таблицы MySQL. Мы также можем ВСТАВИТЬ в таблицу MySQL с помощью Spark [неразборчиво]. Вы также можете создавать внешние таблицы в MySQL с помощью Spark, что было просто невозможно раньше, потому что раньше у нас не было подключаемого модуля каталога.Теперь этот пример будет доступен в Spark 3.1, когда мы закончим [неразборчиво].
Когда использовать Data Source V2 API?
У некоторых людей могут возникнуть вопросы. Теперь у Spark есть оба — у него есть API V1 и V2 — какой из них я должен использовать? В общем, мы хотим, чтобы все перешли на V2 [неразборчиво]. Но API V2 еще не готов, так как нам нужно больше отзывов, чтобы усовершенствовать API. Вот несколько советов о том, когда выбрать V2 API. Итак, если вы хотите [неразборчиво], то это функция каталога, значит, это должна быть версия 2, потому что API версии 1 не имеет такой возможности.Если вы хотите поддерживать обе версии потоковой передачи в своем источнике данных, вам следует использовать V2, потому что в V1 потоковая передача и [неразборчиво] — разные API, что затрудняет повторное использование кода. А если вам важна производительность сканирования, вы можете попробовать V2 API, потому что он позволяет сообщать о предоставлении данных [неразборчиво] в Spark, а также позволяет реализовать [неразборчиво] считыватель для повышения производительности.
Если вас это не волнует, и вы просто хотите [неразборчиво] один раз сделать исходный код и изменить его, пожалуйста, используйте V1, так как V2 не очень стабилен.
Расширяемость и экосистема
Экосистема также очень быстро развивается. В этом выпуске Spark можно лучше интегрировать в экосистему, поддерживая более новую версию таких общих компонентов, как Java 11, Hadoop 3, Hadoop 3 [неразборчиво] и Hadoop 2.3 [неразборчиво]. Я хочу упомянуть здесь некоторые критические изменения.
Начиная с этого выпуска, мы собираем Spark только с Scala 2.12, поэтому Scala 2.11 больше не [неразборчиво]. И мы устарели и на Python 2, потому что это конец жизни.В загружаемом образе мы поместили сборку Spark с различными [неразборчиво] и комбинациями Hadoop. По умолчанию это будет Hadoop 2.7 и 2.3 [исключение?]. Доступны еще две [компании?] Превью. Одним из них является исполнение Hadoop 2.7 и Hadoop 1.2, предназначенное для людей, которые не могут обновить свои конечные формы. Другой — исполнение Hadoop 3.2 и Hadoop 2.3, предназначенное для людей, которые хотят попробовать Hadoop 3. Мы также расширяем поддержку различных версий Hadoop и Hive с 0.12 к 3.1.
Улучшения документации
Улучшения документации — это последняя существующая новость, которой я хочу поделиться со всеми. Как читать в стандартном веб-интерфейсе — это частый вопрос для многих новых пользователей Spark. Это особенно актуально для пользователей Spark SQL и пользователей потоковой передачи Spark. Они используют [неразборчиво]. Обычно они не знают, что это такое и в чем наша работа [неразборчиво]. Кроме того, [неразборчиво] используют множество запросов и имен матриц, которые не очень понятны многим пользователям.Начиная с этого выпуска, мы добавляем новый раздел для [неразборчиво] чтения веб-интерфейса. Он включает в себя [неразборчиво] страницу задания и [неразборчиво], а также потоковую передачу SQL [неразборчиво]. Это только начало. Мы продолжим его улучшать, а затем справочник по SQL.
Наконец, в этом выпуске уже есть справочник по SQL для Spark SQL. Spark SQL — самый популярный и важный компонент Spark. Однако у нас не было собственного справочника по SQL для определения [семантического?] И подробного поведения SQL. Позвольте мне быстро просмотреть основные главы справочника по SQL.Итак, у нас есть страница с объяснением ANSI-компонентов Spark. Итак, как я упоминал ранее, у нас есть совместимость с SQL, но чтобы избежать [исправления?] Запросов [выполняющих?], Мы делаем это необязательным. Таким образом, вы можете включить совместимость с ANSI, только включив этот флаг.
У вас также есть страница с подробным объяснением семантики каждого [неразборчиво], чтобы вы могли знать, что это означает и как они себя ведут. У вас также есть страница с объяснением данных и партнерских строк, используемых для функций форматирования и синтаксического анализа [неразборчиво].Также есть страница с документами для каждой функции в Spark. У нас также есть страница с объяснением синтаксиса и определения таблицы или функции [неразборчиво]. Кроме того, есть страница с объяснением синтаксиса и семантики каждого [неразборчиво] в Spark SQL.
Также есть страница с объяснением нулевой семантики. null — это особое значение в Spark SQL и других экосистемах. Таким образом, должна быть страница, на которой можно было бы объяснить, что означает значение null в пустых запросах. Кроме того, у нас есть страница с объяснением синтаксиса всех команд, таких как команды DDL и DML, а также вставка также включена в документ.Фактически, SELECT имеет так много функций, поэтому нам нужна страница, чтобы объяснить их все. Да, есть также страница для других специальных команд, таких как SHOW TABLES .
Наконец, [неразборчиво]. Это еще одно важное усовершенствование в документе Spark 3.0. В этом выпуске для всех компонентов есть [неразборчиво] руководства. Когда вы обновляете свою версию Spark, вы можете внимательно их прочитать и, по сути, [неразборчиво]. Вам может быть интересно, почему он намного длиннее, чем предыдущая версия.Это потому, что мы стараемся задокументировать все важные изменения внешнего вида, которые вы хотите услышать. Если при обновлении возникают какие-то ошибки, это еще один многословный документ или слегка сбивающее с толку сообщение об ошибке, пожалуйста, откройте заявку, и мы постараемся исправить ее в следующих выпусках.
Этому Спарку почти 10 лет. Сообщество Spark очень серьезно относится к изменениям. И мы изо всех сил стараемся избегать [неразборчиво] изменений. Если вы обновитесь до Spark 3.0 в это время, вы можете увидеть явные сообщения об ошибках об изменении.Таким образом, сообщение об ошибке также предоставляет имена конфигурации, чтобы вы могли либо вернуться к существующему поведению, либо перейти к новому поведению.
В этом докладе мы говорили о многих интересных функциях и улучшениях в Spark 3.0. Из-за нехватки времени есть еще много других приятных функций, которые не рассматриваются в этом докладе. Пожалуйста, скачайте Spark 3.0 и попробуйте сами.
Вы также можете попробовать [неразборчиво] Databricks [неразборчиво] 10.0 beta. Все новые функции уже доступны. Community Edition предоставляется бесплатно.Без вклада всего сообщества выпустить такой успешный релиз невозможно. Спасибо всем коммиттерам Spark по всему миру. Спасибо. Всем спасибо.
Кузница лося
Искровые испытания и искровые испытания металлов
Аааа, искровый тест. Этот незаменимый инструмент / тест при сортировке металлов / сплавов использовался, по крайней мере, в течение последних нескольких столетий вместе с магнитным тестом. Благодаря стандартизации металлов можно довольно легко различать многие типы сплавов, просто глядя на поток искр, который они выбрасывают (конечно, с небольшой практикой) … О, и прежде чем начинать искровое испытание, убедитесь, что вы иметь достаточно большой образец металла.Если он настолько тонкий, что просто плавится, то точной искровой струи у вас не получится.
Первое, что вам нужно сделать, это найти какую-нибудь болгарку. Следует использовать настольную шлифовальную машину, а не угловую шлифовальную машину и т.п. Кроме того, я бы предпочел держать образец, а не измельчитель, и таким образом я мог бы получить хороший устойчивый поток искр благодаря контролю. Я попытался написать хорошее описание искр металла, но, по правде говоря, это информационное изображение В 100 раз лучше письменного описания.Вот это удивительное фото, которое я нашла в очень старом журнале.
Сравнение искры: вид искры полезен только в том случае, если вы знаете, как она должна выглядеть! Поэтому над шлифовальным кругом в моем магазине вы найдете небольшую коробку для рыболовных снастей с небольшими образцами из разных металлов. В каждом отсеке у меня есть разные металлы / сплавы, с которыми я сталкивался за последние несколько лет. (включая немного Титана). Все эти металлы производят очень разные типы искр, которые любой продавец должен легко идентифицировать.В идеале, каждый должен иметь в своем магазине или гараже небольшую хозяйственную коробку, заполненную образцами различных типов маркированных металлов. Когда вы сталкиваетесь со сплавом, который необходимо идентифицировать, проведите магнитный тест. Это сузит многие сплавы в вашей коробке. Затем сделайте перекрестную ссылку на искры вашего образца с искрами известных вам металлов.
Обратите внимание на достойные характеристики:- Количество вилок / веток пропорционально содержанию углерода в металле.Чем больше углерода, тем больше таких всплесков вы увидите в конце искры
- Цвет поможет определить состав сплава. Самые темные красные искры исходят от никеля, кобальта и карбида вольфрама
- Изумительно БЕЛЫЕ искры означает ТИТАН! Самые великолепные искры, которые я когда-либо видел, — это искры из титана. Они невероятно БЕЛЫЕ и светятся!
- NO Sparks означает, что металл цветной.Это особенно хорошо для того, чтобы отличить нержавеющую сталь от алюминия.
Для создания искр обычно используют настольную шлифовальную машину, но иногда это неудобно, поэтому используется переносная шлифовальная машина. В любом случае шлифовальный круг должен иметь соответствующую поверхностную скорость, по крайней мере, 23 м / с (4500 поверхностных футов в минуту (sfpm)), но должна быть между 38 и 58 м / с (7500–11 500 sfpm). Круг должен быть грубым и твердым, поэтому часто используют оксид алюминия или карборунд.Испытательная зона должна находиться в месте, где нет яркого света, падающего прямо в глаза наблюдателя. Кроме того, шлифовальный круг и окружающая область должны быть темными, чтобы можно было четко видеть искры. Затем испытуемый образец слегка касается шлифовального круга для образования искр. [1] [2]
Важными характеристиками искры являются цвет, объем, характер искры и длина. Обратите внимание, что длина зависит от величины давления, приложенного к шлифовальному кругу, поэтому это может быть плохим инструментом для сравнения, если давление не совсем одинаковое для образцов.Кроме того, шлифовальный круг необходимо часто править для удаления металлических отложений. [1] [2]
Метод сжатого воздуха
Другой менее распространенный метод создания искр — это нагрев образца до красного тепла с последующим подачей сжатого воздуха на образец. Сжатый воздух обеспечивает достаточное количество кислорода для воспламенения образца и образования искр. Этот метод более точен, чем использование шлифовального станка, поскольку он всегда дает искры одинаковой длины для одного и того же образца. Сжатый воздух создает каждый раз одно и то же «давление».Это делает наблюдения длины искры гораздо более надежной характеристикой для сравнения. [4]
Автоматизированное искровое испытание
Автоматизированное искровое испытание было разработано, чтобы избавить от необходимости полагаться на навыки и опыт оператора и тем самым повысить надежность. Система полагается на спектроскопию, спектрометрию и другие методы для «наблюдения» искровой картины. Было обнаружено, что эта система может определять разницу между двумя материалами, которые выделяют
Кованое железо искр истекают прямыми линиями.Хвосты искр расширяются к концу, как лист. [1] [5]
Низкоуглеродистая сталь Искры похожи на искры из кованого железа, за исключением того, что у них будут крошечные вилки, а их длина будет больше различаться. Искры будут белого цвета. [1] [5]
Среднеуглеродистая сталь имеет большее раскалывание, чем низкоуглеродистую сталь, и широкий диапазон искр, причем больше у шлифовального круга. [5]Высокоуглеродистая сталь имеет густую искровую диаграмму (много разветвлений), которая начинается на шлифовальном круге.Искры не такие яркие, как искры из среднеуглеродистой стали. [5]
Марганцовистая сталь имеет искры средней длины, которые дважды раздваиваются перед окончанием. [5]
Быстрорежущая сталь имеет слабую красную искру, которая вспыхивает на конце. [5]
Искры из нержавеющей стали серии 300 не так плотны, как искры из углеродистой стали, не раскалываются и имеют цвет от оранжевого до соломенного. [2]
Искры из нержавеющей стали серии 310 намного короче и тоньше, чем искры серии 300.Они имеют цвет от красного до оранжевого и не разветвляются. [2]
Искры серии 400 похожи на искры серии 300, но немного длиннее и имеют вилки на концах искр. [2]
Чугун имеет очень короткие искры, которые начинаются на шлифовальном круге. [1]
Никель и кобальтовые жаропрочные сплавы искры тонкие и очень короткие, они темно-красного цвета и не разветвляются. [2]
Твердый сплав имеет искры менее 3 дюймов, темно-красного цвета и не раскалываются.[6]
Титан — это цветной металл, он дает много искр. Эти искры легко отличить от черных металлов, так как они очень яркого, ослепляющего белого цвета. [7]
Источник: Википедия http://en.wikipedia.org/wiki/File:Spark_testing_2.png Английский: Схема искр для искровых испытаний различных типов стали. Ключ:
- Высокоуглеродистая сталь
- Марганцовистая сталь
- Вольфрамовая сталь
- Молибденовая сталь
- Кованое железо
- Низкоуглеродистая сталь
- Сталь с 0.От 5 до 0,85% углерода
- Инструментальная сталь высокоуглеродистая
- Быстрорежущая сталь
- Марганцовистая сталь
- Мушет сталь
- Специальная магнитная сталь
Список литературы
- а б в г д е Гири 1999, стр. 63.
- а б в г д е ж з Davis & ASM International 1994, стр. 126–127.
- a b The Engineering Magazine 1910, стр. 262–265.
- Saunders 1908, стр. 4808–4810.
- a b c d e f Lee 1996, p.22.
- Вудсон, К. У. (сентябрь 1959 г.), «Искровые потоки определяют металлы», Popular Mechanics 112 (3): 192–193, ISSN 0032-4558.
- «Титан или простая сталь?». Проверено 21 февраля 2011.
- Макс Берманн впервые сообщил о методе искрового испытания на 5-й конференции Международной ассоциации по испытанию материалов, которая проходила в Копенгагене, как сообщает журнал Engineering Magazine. На основании информации о том, что конференция проводилась в Копенгагене, год можно найти по адресу:
- «Копенгагенский конгресс по испытаниям строительных материалов», Nature 81 (2082): 377–378, 1909-10-23, DOI: 10.1038 / 081377a0, архивировано 18 мая 2010 г.
- François, D .; Пино, Андре (2002), От Шарпи до испытаний на удар в настоящем, Elsevier, стр. 7, ISBN 978-0-08-043970-9
- Oberg & Jones 1918, стр. 88–92.
- Drozda et al. Бакерджян, стр. 7-18.
Мама, посмотри, что еще я нашла!
- начало списка видео, книг, ссылок и т. Д. Для получения дополнительных сведений
| Мудрость моего отца: «Человеку нужно больше, чтобы уйти от битвы, чем остаться и сражаться.» | |
IRIDIUM TT — Характеристики | Продукты | СВЕЧА ЗАЖИГАНИЯ | Автозапчасти и аксессуары
Структура
DENSO начала продавать свечи зажигания IRIDIUM TT с центральным электродом из иридиевого сплава диаметром 0,4 мм и заземляющим электродом из сплава платины игольчатого типа 0,7 мм.
Эффект гашения был уменьшен за счет придания электроду формы двойной иглы.В результате ядро пламени быстро развивается, и мощность двигателя раскрывается до максимума.
1 Встроенный высоконадежный резисторВсе типы спецификаций включают встроенный высоконадежный монолитный резистор для устранения электромагнитных помех от всех видов электронных устройств.
2 Лазерная сварка 360 °
Иридиевый наконечник монтируется методом «круговой лазерной сварки», который обеспечивает высокую надежность даже в самых тяжелых условиях вождения.
3 Игольчатый платиновый заземляющий электрод φ0,7 мм
Чтобы максимально предотвратить эффект гашения, заземляющий электрод должен быть как можно меньше. Традиционные заземляющие электроды нельзя было сделать слишком маленькими без снижения прочности заземления или увеличения износа электродов.
Однако нам удалось прикрепить тонкий платиновый электрод диаметром 0,7 мм, используя технику лазерной сварки на 360 °.
4 Центральный электрод из ультратонкого иридия φ0,4 мм
Благодаря использованию эксклюзивного иридиевого сплава DENSO с очень высокой температурой плавления кончик центрального электрода может иметь очень тонкую и тонкую форму, что снижает требования к искровому напряжению и значительно улучшает воспламеняемость.
Рост пламени
На фотографии видно пламя, отраженное изменением плотности. На рис. 1 показаны результаты исследования влияния формы электрода на рост пламени с использованием иридиевых свечей зажигания и IRIDIUM TT.
На фотографиях видно, что в случае иридиевой свечи зажигания уменьшение размера зазора (с 1,1 мм до 0,6 мм) препятствовало росту пламени, в то время как в случае IRIDIUM TT рост пламени был значительным и превышал иридиевой свечи зажигания, несмотря на суженный искровой промежуток (0.6 мм). Эти наблюдения показывают, что, как показали результаты моделирования зажигания / зажигания, электрод с тонким заземлением может снизить необходимое напряжение, поскольку он позволяет сделать искровой промежуток более узким, обеспечивая при этом более высокую воспламеняемость, чем иридиевая свеча зажигания.
Преимущества электродов с тонким заземлением
Для снижения необходимого напряжения и улучшения характеристик стрельбы. Использованы самые передовые технологии в мире.
для использования электрода диаметром 0,4 мм в IRIDIUM TT.
Чем меньше размер электрода, тем более концентрированный электрический потенциал на кончике электрода и тем сильнее электрическое поле, которое влияет на требуемое напряжение, и тем ниже требуемое напряжение. В результате сгорание подходит для всех типов вождения, двигатель легко запускается, а ускорение улучшается.
Выше показана напряженность электрического поля в случае определенных изменений напряжения на вилке Iridium и IRIDIUM TT.
Чем больше становится напряженность электрического поля, тем легче запускать огонь с низким напряжением.
* 1 FEM (анализ методом конечных элементов): Общий метод измерения напряженности электрического поля.
Повышенная воспламеняемость
На фиг.3 показаны результаты оценки того, как направление выступа миниатюрной части может влиять на воспламеняемость двигателя. Оценка проверила холостой ход при равном открытии дроссельной заслонки с выключенным ISC (регулировка холостого хода). Более высокая частота вращения холостого хода означает более высокую воспламеняемость.
На этом рисунке показаны результаты оценки IRIDIUM TT.Этот рисунок показывает, что IRIDIUM TT превосходит иридиевые свечи зажигания по воспламеняемости.
Лучшая топливная экономичность
На рис. 4 показаны результаты исследования изменения сгорания и расхода топлива с использованием четырехцилиндрового двигателя объемом 1800 куб. См. Оценка проводилась путем включения ISC и установки средней скорости вращения двигателя на 800 об / мин (на холостом ходу). В этом исследовании использовался ранее указанный тип 1 IRIDIUM TT. Pmi COV (коэффициент вариации) на диаграмме показывает колебания IMEP (указанное среднее эффективное давление).Как видно из этого рисунка, IRIDIUM TT может снизить Pmi COV примерно на 3,1% и, соответственно, снизить расход топлива на 2,4% по сравнению со свечой зажигания Iridium. Эти преимущества достигаются благодаря тому, что миниатюризация заземляющего электрода обеспечивает лучшую воспламеняемость, повышая эффективность сгорания. Поскольку IRIDIUM TT имеет низкую вариацию сгорания и позволяет снизить скорость холостого хода, можно ожидать дальнейшего улучшения топливной экономичности.
1. Введение в анализ данных с помощью Spark
Проект Spark содержит несколько тесно интегрированных компонентов.По своей сути Spark — это «вычислительный механизм», который отвечает за планирование, распределение и мониторинг приложений, состоящих из множества вычислительных задач на многих рабочих машинах или вычислительном кластере . Поскольку основной механизм Spark является быстрым и универсальным, он поддерживает несколько высокоуровневых компонентов, специализирующихся на различных рабочих нагрузках, таких как SQL или машинное обучение. Эти компоненты разработаны для тесного взаимодействия, что позволяет объединять их как библиотеки в программном проекте.
Философия тесной интеграции имеет несколько преимуществ. Во-первых, все библиотеки и компоненты более высокого уровня в стеке выигрывают от улучшений на более низких уровнях. Например, когда основной движок Spark добавляет оптимизацию, библиотеки SQL и машинного обучения также автоматически ускоряются. Во-вторых, затраты, связанные с запуском стека, сводятся к минимуму, потому что вместо запуска 5–10 независимых программных систем организации необходимо запустить только одну. Эти затраты включают развертывание, обслуживание, тестирование, поддержку и другие.Это также означает, что каждый раз, когда новый компонент добавляется в стек Spark, каждая организация, использующая Spark, сразу же сможет опробовать этот новый компонент. Это меняет стоимость опробования нового типа анализа данных от загрузки, развертывания и изучения нового программного проекта до обновления Spark.
Наконец, одно из самых больших преимуществ тесной интеграции — это возможность создавать приложения, которые легко сочетают в себе различные модели обработки. Например, в Spark вы можете написать одно приложение, которое использует машинное обучение для классификации данных в реальном времени по мере их поступления из потоковых источников.Одновременно аналитики могут запрашивать результирующие данные также в режиме реального времени с помощью SQL (например, для объединения данных с неструктурированными файлами журнала). Кроме того, более опытные инженеры и специалисты по обработке данных могут получить доступ к одним и тем же данным через оболочку Python для специального анализа. Другие могут получить доступ к данным в автономных пакетных приложениях. Все это время ИТ-отдел должен поддерживать только одну систему.
Здесь мы кратко представим каждый из компонентов Spark, показанных на рис. 1-1.
Рисунок 1-1.Стек искры
Spark Core
Spark Core содержит базовые функции Spark, включая компоненты для планирования задач, управления памятью, восстановления после сбоев, взаимодействия с системами хранения и т. Д. Spark Core также является домом для API, который определяет устойчивых распределенных наборов данных (RDD), которые являются основной абстракцией программирования Spark. СДР представляют собой набор элементов, распределенных по множеству вычислительных узлов, которыми можно управлять параллельно. Spark Core предоставляет множество API для создания этих коллекций и управления ими.
Spark SQL
Spark SQL — это пакет Spark для работы со структурированными данными. Он позволяет запрашивать данные через SQL, а также через вариант SQL Apache Hive, называемый Hive Query Language (HQL), и поддерживает множество источников данных, включая таблицы Hive, Parquet и JSON. Помимо предоставления интерфейса SQL для Spark, Spark SQL позволяет разработчикам смешивать запросы SQL с программными манипуляциями с данными, поддерживаемыми RDD в Python, Java и Scala, и все это в одном приложении, тем самым объединяя SQL со сложной аналитикой.Эта тесная интеграция с богатой вычислительной средой, предоставляемой Spark, делает Spark SQL непохожим на любой другой инструмент хранилища данных с открытым исходным кодом. Spark SQL был добавлен в Spark в версии 1.0.
Shark был более старым проектом SQL-on-Spark Калифорнийского университета в Беркли, который модифицировал Apache Hive для работы на Spark. Теперь он был заменен на Spark SQL, чтобы обеспечить лучшую интеграцию с механизмом Spark и языковыми API.
Spark Streaming
Spark Streaming — это компонент Spark, который позволяет обрабатывать живые потоки данных.Примеры потоков данных включают файлы журналов, генерируемые рабочими веб-серверами, или очереди сообщений, содержащие обновления статуса, отправленные пользователями веб-службы. Spark Streaming предоставляет API для управления потоками данных, который близко соответствует API RDD Spark Core, что позволяет программистам легко изучать проект и перемещаться между приложениями, которые манипулируют данными, хранящимися в памяти, на диске или поступающими в режиме реального времени. В основе своего API Spark Streaming был разработан для обеспечения такой же степени отказоустойчивости, пропускной способности и масштабируемости, что и Spark Core.
MLlib
Spark поставляется с библиотекой, содержащей общие функции машинного обучения (ML), которые называются MLlib. MLlib предоставляет несколько типов алгоритмов машинного обучения, включая классификацию, регрессию, кластеризацию и совместную фильтрацию, а также поддерживает такие функции, как оценка модели и импорт данных. Он также предоставляет некоторые примитивы машинного обучения нижнего уровня, включая общий алгоритм оптимизации градиентного спуска. Все эти методы предназначены для масштабирования в кластере.
GraphX
GraphX - это библиотека для управления графами (например, графом друзей в социальной сети) и выполнения вычислений, параллельных графам. Подобно Spark Streaming и Spark SQL, GraphX расширяет Spark RDD API, позволяя нам создавать ориентированный граф с произвольными свойствами, прикрепленными к каждой вершине и ребру. GraphX также предоставляет различные операторы для управления графами (например, subgraph и mapVertices ) и библиотеку общих алгоритмов графов (например,g., PageRank и подсчет треугольников).
Менеджеры кластера
Под капотом Spark разработан для эффективного масштабирования от одного до многих тысяч вычислительных узлов. Для достижения этого при максимальной гибкости Spark может работать с различными диспетчерами кластеров , включая Hadoop YARN, Apache Mesos и простой диспетчер кластеров, включенный в сам Spark и называемый автономным планировщиком. Если вы просто устанавливаете Spark на пустой набор машин, автономный планировщик предоставляет простой способ начать работу; Однако если у вас уже есть кластер Hadoop YARN или Mesos, поддержка Spark этих менеджеров кластеров позволяет вашим приложениям также работать на них.В главе 7 рассматриваются различные варианты и способы выбора подходящего менеджера кластера.
.